CS554 Syllabus & Progress
CS554 - Advanced Database Systems
Syllabus and Progress
-
Introduction
-
Review of undergraduate database material
(my CS377 class notes is here:
click here )
-
Review of Relational Algebra:
-
Review of SQL:
- Accessing the SQL database software:
- Accessing the MySQL
server:
click here
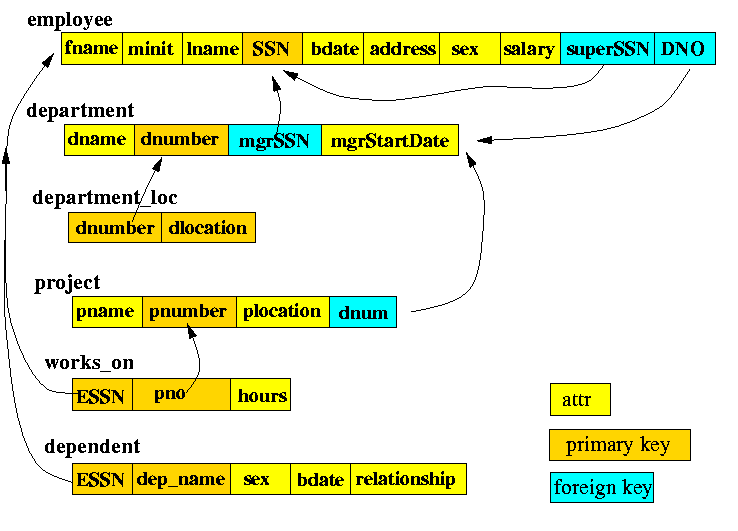
- The model of the
Company database used
in these notes:
click here
- Intro to SQL:
click here
------
- Intro to the
SELECT command
- Qualifying attributes and aliasing:
click here
------
- The tuple conditions
that can be used in the where clause:
click here
------
- Nested queries:
- Correlated nested queries:
- Useful trick to get other attributes using a set of foreign keys
in a nested query:
click here
------
- Set functions:
- Forming groups based on grouping attributes and
conditions on a group:
- Forming groups that have common attribute values:
- Conditions on a group:
- Virtual table (relation) or view:
click here
------
Homework 2:
click here
Accessing data stored on disk
-
Secondary Storage (Disks) management
- Storing data files on disks:
------
- Techniques to speed up disk operations:
Lecture slides ***
------
- Handling disk failures (RAID):
- How to store (data) records on disks:
handwritten notes
- How the DBMS locate records (on disks and in memory - pointer swizzling):
handwritten notes
This section uses
hashing -- read about
hashing here:
click here
- Identifying blocks/records:
- The block/record locating problem:
- Speeding up block/records access --- pointer swizzling:
Homework 3:
click here
-
Indexing
- Introduction (definitions):
- B-tree and B+-tree:
- Structure of the B/B+-tree:
- Searching in a B-tree and B+-tree:
click here
- Inserting a key into a B-tree and B+-tree:
- Deleting a key into a B-tree and B+-tree:
- Deleting (key, recordPtr) from (a leaf node of)
the B+-tree:
click here
- Deleting (key, rightTreePtr) from a internal node
of the B+-tree:
click here
- Examples of deletions in the B+-tree:
click here (+ slides)
- Hashing-based indexes:
- Multi-dimensional indexes:
- Intro -- multi-dimenisional information:
click here (+ slides)
- Commonly used queries on multi-dimenisional information:
click here (+ slides)
- Motivation for Multi-dimensional indexes:
click here (+ slides)
- Overview Multi-dimensional indexes:
click here
- Table-based multi-dimensional indexes:
- Grid index Files:
- Partitioning hash function:
- Tree-like (tree-based) multi-dimensional indexes:
- Multiple-key index:
- kd (k-dimensional) tree:
- The Quad-tree:
- The Region (R) tree:
(paper: click here)
- Bitmap indexes:
Homework 4:
click here
Query processing
-
Cost and constraint on
query execution (= processing a physical query plan)
-
One-pass Algorithms for
Query execution (processing a physical query plan)
- One-pass algorithms of Physical Operators:
- Unary operators:
- Binary operators:
- Summary:
click here
-
The nested-loop Algorithms for
Cartesian Product and Join
-
2-pass Algorithms for
Query execution that are based on
hashing
- Intro to
two-pass algorithms:
click here (+ slides)
- Introduction to 2-pass hashing-based algorithms:
click here (+ slides)
- Unary operators:
- Selection σ:
click here
***
- Projection π:
click here
***
- Duplicate elimination δ:
click here (+ slides)
+++ 1st presentation
- Partition R using hashing
- Process each partition using the one-pass algorithm
- Grouping γ:
click here (+ slides)
+++ 2nd presentation
- Partition R using hashing
- Process each partition using the one-pass algorithm
- Binary operators:
- Union ∪
- Bag union:
click here
***
- Set union:
click here (+ slides)
+++ 1st presentation
- Partition R and S using hashing
- Process each partition using the one-pass algorithm
- Intersection ∩
- Bag intersection:
click here (+ slides)
+++ 2nd presentation
- Partition R and S using hashing
- Process each partition using the one-pass algorithm
- Set intersection:
click here (+ slides)
+++ 3rd presentation
- Partition R and S using hashing
- Process each partition using the one-pass algorithm
- Difference −
- Bag difference:
--- same procedure as in the
+++ presentation
- Partition R and S using hashing
- Process each partition using the one-pass algorithm
- Set difference:
--- same procedure as in the
+++ presentation
- Partition R and S using hashing
- Process each partition using the one-pass algorithm
- Product (cartesian product) ×
click here (+ slides)
***
- Join ⋈:
click here (+ slides)
--- same procedure as in the
+++ presentation
- Partition R and S using hashing
- Process each partition using the one-pass algorithm
- Summary:
click here
-
2-pass Algorithms for
Query execution that are based on
(TPMMS) sorting
- The two-pass multiway merge sort (TPMMS)
algorithm
- Unary operators:
- Binary operators:
- Union ∪
- Intersection ∩
- Difference −
- Product (cartesian product) ×
--- same comment as
click here
- Join ⋈:
- Summary:
click here
-
Multi-pass algorithms
-
Algorithms that are based on
indexing:
Query optimization
-
Overview: query optimization:
click here (+ slides)
-
Parsing and pre-processing
- Parsing and pre-processing:
-
Converting a Parse Tree into an initial logical query plan (tree)
- Converting an SQL command that does
not contain a sub-query:
click here (+ slides)
- Converting an SQL command that
contains a sub-query:
- Postscript:
click here
-
Algebraic Laws used
to transform/optimize logical query plans
-
Heuristic-based approach to finding
the optimal logical query plan
-
Prelude to cost-estimation-based approach to finding
the optimal join ordering:
cost estimation
- Intro to finding the best join ordering:
click here (+ slides)
- Estimating the cost of a logical query plan:
click here (+ slides)
- Estimating the number of tuples output
(produced) by
relational algebra operations:
- Using histogram information to
estimate the
result set of join operations:
Homework 6:
click here
-
Cost-estimation-based approach to find the optimal join ordering
- Intro:
click here (+ slides)
- The simplest case: choosing a join order for
R⋈S (R⋈S or S⋈R ?):
click here (+ slides)
- Left-deep trees:
- Finding the best left-deep join tree:
- The Dynamic Programming approach
(= exhaustive search):
-
A greedy heuristic to find the best
left-deep join ordering:
-
The physical query plan
Homework 7:
click here
Ensuring database consistency
-
Recoverability: protecting database from system failure (logging)
- Ensuring database integrity against system failures ----
intro to logging
click here (+ slides)
- Correctness model in Database Systems
- Intro to logging:
click here (+ slides)
- Undo logging:
- Checkpointing the undo log:
- Redo logging:
- Intro to redo logging (redo-log write rule):
click here (+ slides)
- Recovery using to redo logging:
- Nonquiescent Checkpointing for REDO log:
- Performing a nonquiescent checkpoint on a REDO log:
click here (+ slides)
- Recovering using a checkpointed REDO log:
click here (+ slides)
- Undo/Redo logging:
- Intro to Undo/redo logging:
click here (+ slides)
- Recovery using to Undo/redo logging:
- Nonquiescent Checkpointing for undo/redo log:
Homework 8:
click here
-
Serializability: correctness of concurrent execution of transactions
- Intro to concurrency control:
click here
- Serializability:
- Conflict-serializability:
a more practical type of serializability
- Conflicting operations:
click here
- Conflict-serializable schedules (conflict-serializability):
click here
- Precedence graph test for conflict-serializability:
click here
- Proof of correctness of the precedence graph test:
click here
- Exclusive locks:
- Intro to locks:
click here
- Exclusive locks:
click here
- 2-phase locking (sufficient for enforcing
conflict-serializability):
- Deadlocks:
click here
- Shared/Exclusive locking:
- Upgrading locks:
- Read first and write later - upgrading a lock ?:
click here
- Upgrading locks: the new
"update lock" locking mode:
click here
- Increment/decrement locking:
- Implementation of locks:
-
Serializability and Recoverability
- Introduction:
- Interaction between recoverability and serializability:
click here
- Cascading rollbacks:
- Recoverable schedules:
- Recoverable and serializable schedules:
- Intro:
click here
- ACR schedules ---
a subset of recoverable schedules:
- A summary of the schedules:
click here
- Strick 2-phased locking --- enforcing
serializable and recoverable schedules:
click here
-
Deadlock
- Intro:
click here
- Deadlock detection:
- Deadlock prevention:
High-performance (parallel and distributed) database systems
-
Parallel Data Processing Algorithms
- Parallel computer architectures:
click here
- Tuple storage to support/assist parallel algorithms:
click here
- Unary operators:
- Parallel algorithm for selection σ:
click here
- Parallel algorithm for duplicate elimination δ:
click here
- Parallel algorithm for projection π:
click here
- Cost simplification in parallel data processing:
click here
- Parallel algorithm for grouping γL:
click here
- Unary operators:
-
The Map-Reduce Parallelism framework
- MapReduce--- a specific parallel processing pattern:
click here
- Classic (introductory) MapReduce algorithms:
- Compute the inverted index:
click here
- Count the number of occurrence of words in documents:
click here
- MapReduce Algorithm for Matrix Multiplication:
click here
- MapReduce Algorithm for Equi Join:
click here
-
Distributed Databases: query processing
- Introduction:
- Characteristics of Distributed databases:
click here
- Data fragmentation and sharding in
distributed database systems:
click here
- Issues caused by distributed data storage and processing
(atomic commit, locks):
click here
- Distributed query processing - distributed join:
- Query processing in distributed system:
click here
- Cost simplication in distributed data processing:
click here
- Reducing the communication cost using
semi-join (⋉):
click here
- Using bloom filter to eleminate dangling tuples:
click here
- Removing dangling tuples in join of many relations:
- Full reducers:
click here
- Acyclic hypergraphs:
pre-req to finding full reducers:
click here
- Constructing full reducers for acyclic hypergraphs:
click here
-
Commiting Distributed Transactions
-
"Big Data" systems (and NOSQL)
- Introduction to NOSQL systems:
click here
- Characteristic/Emphasis of NOSQL systems
(how to achieve high performance):
click here
- Data model and query languages of NOSQL systems:
click here
- Categories of NOSQL systems:
click here
- The CAP Theory:
click here
- Key-value based NOSQL Systems:
- Document based NOSQL Systems:
click here
- Column based NOSQL Systems:
click here
- Graph DB NOSQL Systems:
click here
{kind=link}