Slideshow:
Parameters used to express the cost/constraint in query processing
Parameters used to express the cost/constraint in query processing
Parameters used to express the cost/constraint in
query processing
When computing the buffer requirements for an operator, only count the amount of buffer needed to hold the inputs
Do not count the amount of buffers needed to hold the output
Because: the output of an operator is sent into the input buffer of the subsequent operator !
Parameters used to express the cost/constraint in query processing
Parameters used to express the cost/constraint in query processing

- Parameters to
express the
cost/constraint in
query processing:
-
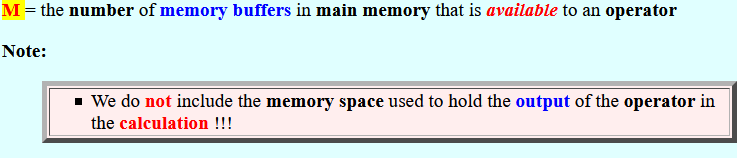
M =
the number of
memory buffers in
main memory that is
available to
an operator
Note:
- We do not include the memory space used to hold the output of the operator in the calculation !!!
-
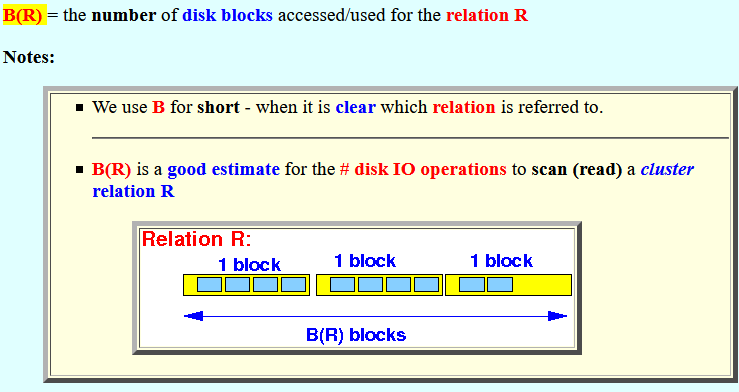
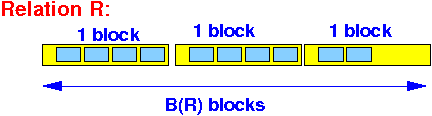
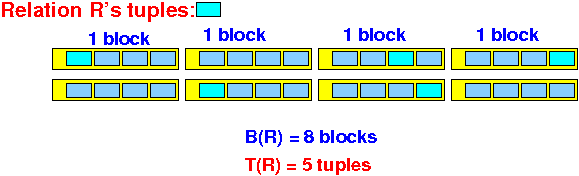
B(R) =
the number of
disk blocks
accessed/used for
the relation R
Notes:
- We use B for short -
when it is clear which
relation is referred to.
- B(R) is a
good estimate for
the # disk IO operations
to scan (read) a
cluster relation R
- We use B for short -
when it is clear which
relation is referred to.
-
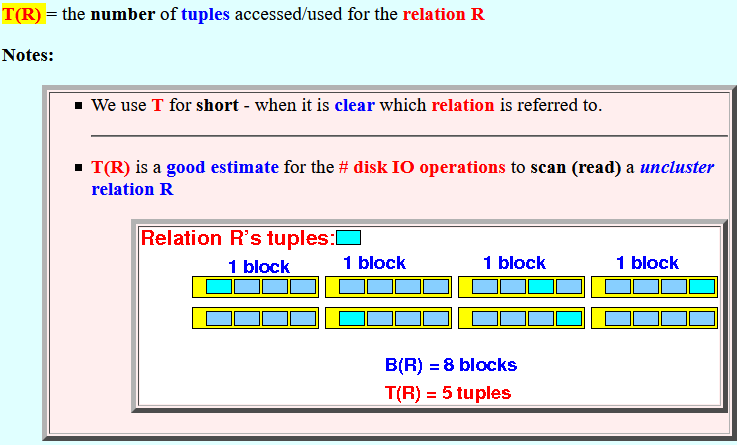
T(R) =
the number of
tuples
accessed/used for
the relation R
Notes:
- We use T for short -
when it is clear which
relation is referred to.
- T(R) is a
good estimate for
the # disk IO operations
to scan (read) a
uncluster relation R
- We use T for short -
when it is clear which
relation is referred to.
-
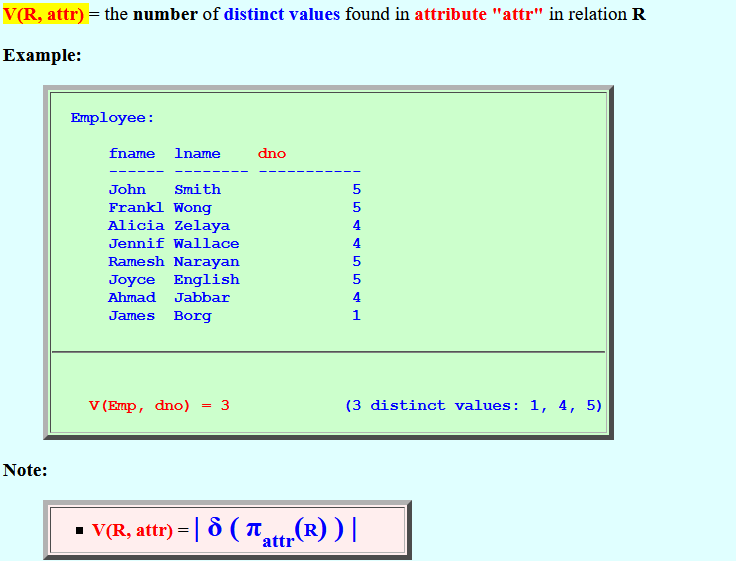
V(R, attr) =
the number of
distinct values found
in attribute "attr" in
relation R
Example:
Employee: fname lname dno ------ -------- ----------- John Smith 5 Frankl Wong 5 Alicia Zelaya 4 Jennif Wallace 4 Ramesh Narayan 5 Joyce English 5 Ahmad Jabbar 4 James Borg 1
V(Emp, dno) = 3 (3 distinct values: 1, 4, 5)Note:
- V(R, attr) = | δ ( πattr(R) ) |
-
V(R,
[a1,a2, ..,an]) =
the number of
distinct values found
in attributes
"a1,a2, .., an" in
relation R
Note:
- V(R, [a1,a2, .., an] ) = | δ ( π a1,a2, .., an (R) ) |
-
M =
the number of
memory buffers in
main memory that is
available to
an operator