- One-pass algorithm:
initialize a search structure H on JOIN attributes of S; /* =========================================================== Phase 1: Use 1 buffer and scan the SMALLER relation first. Build a search structure on the SMALLER relation to help speed up finding common elements. =========================================================== */ while ( S has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { insert t in H; // Build search structure // (hash table or search tree) } } /* ======================================================== Phase 2: Output only those tuples in R that have join attrs equal to some tuple in S We use the search structure H to implement the test t(join attrs) ∈ H efficiently !!! For H, we can use hash table or some bin. search tree ========================================================= */ while ( R has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { if ( t(join attrs) ∈ H ) { Let s = the tuple in H with t(join attrs); output t, s; // successful join } } }
Buffer utilization using M buffers:
- Phase 1:
partition the M buffers as
follows:
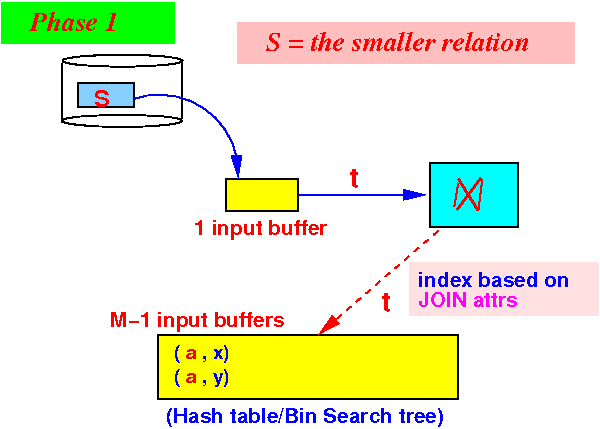
Use 1 buffer for input from S
Use M−1 buffers for the search structure
- Phase 2:
partition the M buffers as
follows:
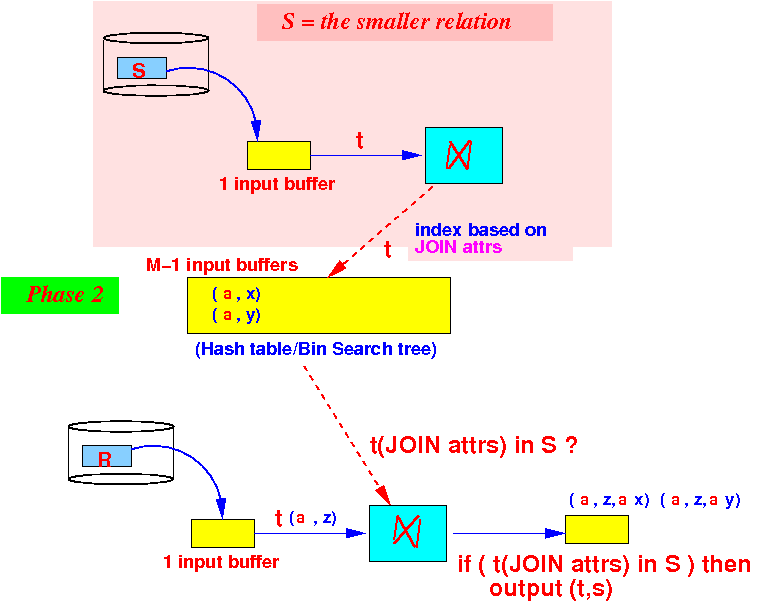
Use 1 buffer for input from R
We are still using M−1 buffers for the search structure in phase 2
- Phase 1:
partition the M buffers as
follows:
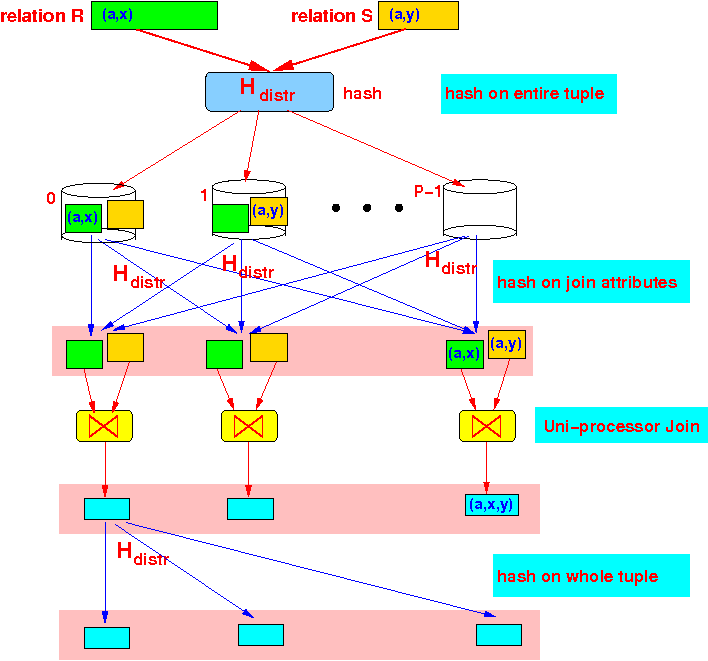
- Parallel algorithm for
R ⋈ S:
- We must
first
re-distribute
both relations
R and S
(using hashing) the
tuples according to the
join attribute values:

- Then:
each processor
executes the
(naive)
uni-processor
R ⋈attrs S operation
locally on its
fragment
of relations R
and S:

- Finally:
re-distribute the
joined tuples
(to distribute load)
- We must
first
re-distribute
both relations
R and S
(using hashing) the
tuples according to the
join attribute values:
- Performance of the
parallel
R ⋈ S:
- Re-distributing the
tuples
in R
and S
according to join attributes:
- Read all
disk blocks
(to perform the hashing re-distribution):
B(R) + B(S) blocks
- Transfer
P-1 ----- of the disk blocks Pto other nodes (assuming uniform distribution of project attribute values)
- Write the
re-distribued tuples
back to disk:
B(R) + B(S) blocks(We assume the relation fragments are very large -- cannot not stored in memory)
- Read all
disk blocks
(to perform the hashing re-distribution):
- Performing
the uni-processor
(single-pass)
R ⋈ S +
re-distribute on
the tuples:
- Read the
tuples from
disk:
B(R) + B(S) blocks
- Re-distribute the
joined tuple
(each joined tuple can be
re-distributed when it is
computed):
variable (depended on join condition....)
- Write the
(join result) tuples to
disk:
0 blocks
(Because the output of the last operation is not counted)
- Read the
tuples from
disk:
Graphically:
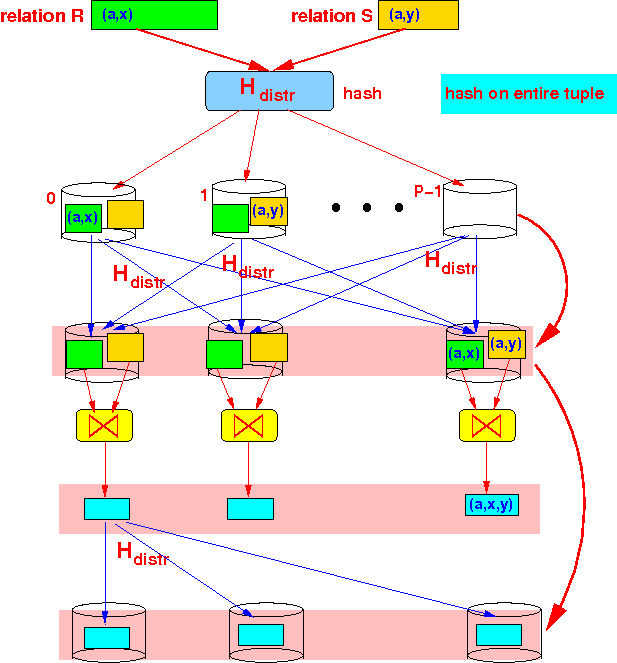
- Re-distributing the
tuples
in R
and S
according to join attributes:
- Total amount of work:
Disk read/write: 2(B(R) + B(S)) + (B(R) + B(S)) blocks - Amount of work
per processor:
2 1 Disk read/write: --- (B(R) + B(S)) + --- (B(R) + B(S)) blocks P P ^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^ Re-hash Single-pass ⋈
(Transfer cost was ignored)