Slideshow:
The set difference
(−S) operator
Note: search (hash) structure need only record the presence of a key (see teaching note in this webpage)
However: we can use the −B algorithm to compute −S
The set difference
(−S) operator
In the slide presentation, I will use the −B algorithm to compute −S ...
The one-pass
set different
S −S R
algorithm
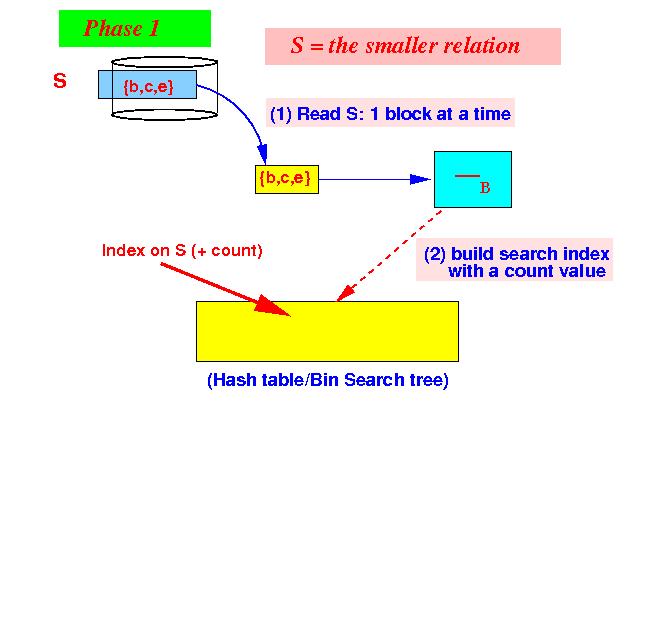
Phase 1: read S and build search index with (key, #occurence)
The one-pass
set different
S −S R
algorithm
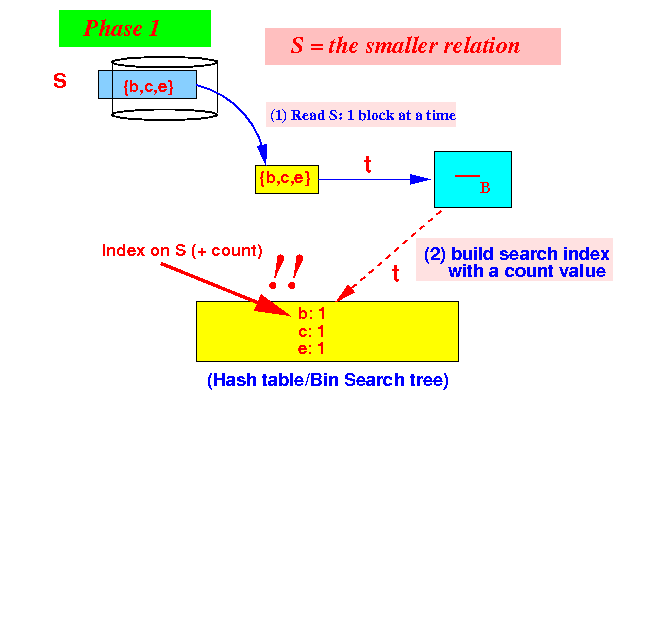
Phase 1: read S and build search index with (key, #occurence)
The one-pass
set different
S −S R
algorithm

Phase 2: scan R and update count in search structure
The one-pass
set different
S −S R
algorithm

Phase 2: scan R and update count in search structure - completed
The one-pass
set different
S −S R
algorithm
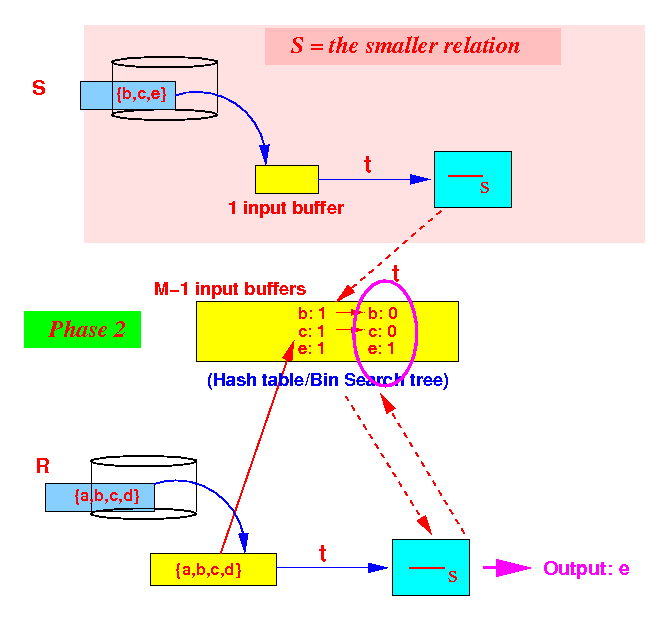
Phase 2: after completion, we can output the set difference
The one-pass
set different
R −S S
algorithm
Phase 1: read S and build search index with (key, #occurence)
The one-pass
set different
R −S S
algorithm
Phase 1: read S and build search index with (key, #occurence)
The one-pass
set different
R −S S
algorithm
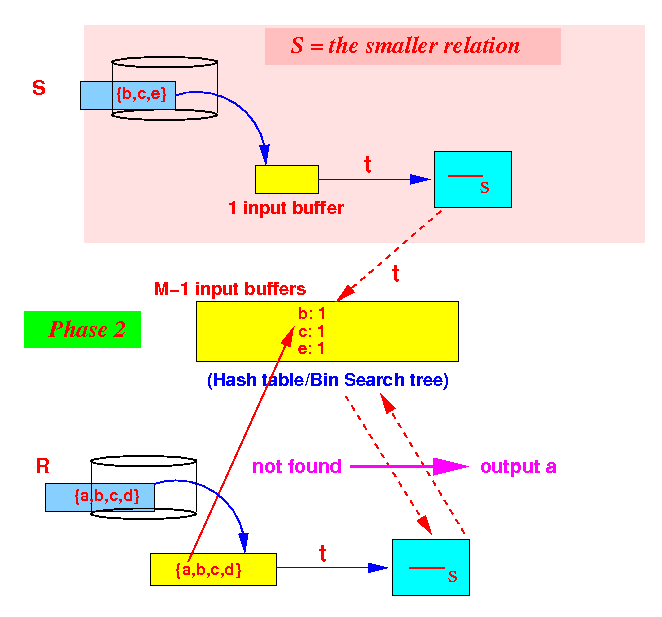
Phase 2: scan R and optionally update count in search structure - if count = 0 (= not found), output tuple
The one-pass
set different
R −S S
algorithm

Phase 2: scan R and optionally update count in search structure - if count > 0 (= found), discard tuple
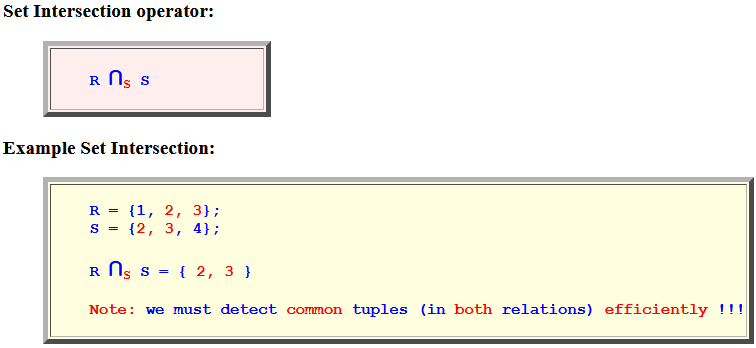
- Set Difference operator:
R −Set S - Example Set Difference:
R = {1, 2, 3}; S = {2, 3, 4}; R −Set S = { 1 }
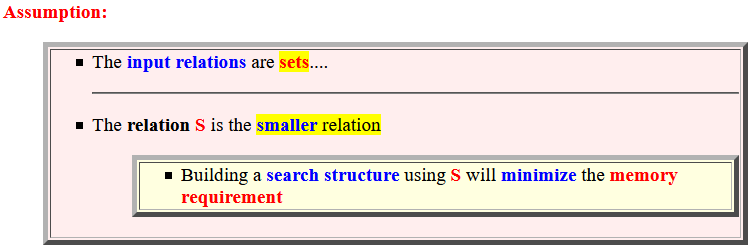
- Assumption:
- The relation S is
the
smaller relation
- Building a search structure using S will minimize the memory requirement
- The relation S is
the
smaller relation
- There are actual
two difference operations:
1. R - S (S is the smaller of the 2 relations) 2. S - R (S is the smaller of the 2 relations)
- Note:
- The set difference algorithm is
similar to the
bag difference algorithm
Except:
- We
do not need to
maintain the
count on
each element
(Because there are no duplicates in a set)
- We
do not need to
maintain the
count on
each element
- The set difference algorithm is
similar to the
bag difference algorithm
- Example:
S = {1, 2, 3, 4}; R = {2, 3, 5, 6, 7}; {1, 2, 3, 4} − {2, 3, 5, 6, 7} = {1, 4}; ^^^^^^^^^^ Index this set
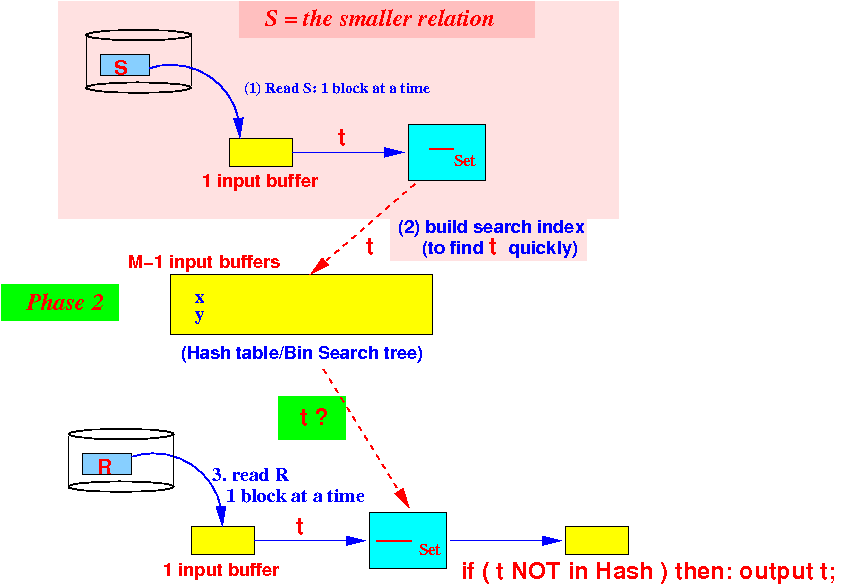
- One-pass algorithm:
initialize a search structure H on all attributes ; /* ============================================================ Phase 1: Use 1 buffer and scan the SMALLER relation first. Build a search structure on the SMALLER relation ============================================================ */ while ( S has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { /* ===================================================== We need a search structure H to implement the test t ∈ H efficiently !!! We can use hash table or some bin. search tree ====================================================== */ insert t in H; } } /* =================================================== Now we know the elements in S =================================================== */ /* ============================================================ Phase 2: output tuples in S Use 1 buffer and scan the other relation. Use the search structure to remove the common elements !! ============================================================ */ while ( R has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { /* ===================================================== We use search structure H to implement the test t ∈ H efficiently !!! We can use hash table or some bin. search tree ====================================================== */ if ( t ∈ H ) { Delete t from H; // t is "subtracted" !!! } else { // Ignore t, it's not in difference ! } } } /* =================================================== ONLY now we can output the difference =================================================== */ for ( every t ∈ H ) { output t ; }
Buffer utilization when there are M buffers available:
- Phase 1:
partition the M buffers as
follows:
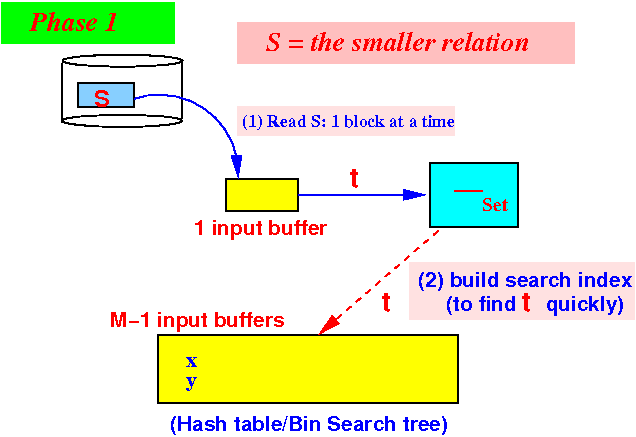
Use 1 buffer for input from S
Use M−1 buffers for the search structure with a count(t) for each unique element in S
- Phase 2:
partition the M buffers as
follows:
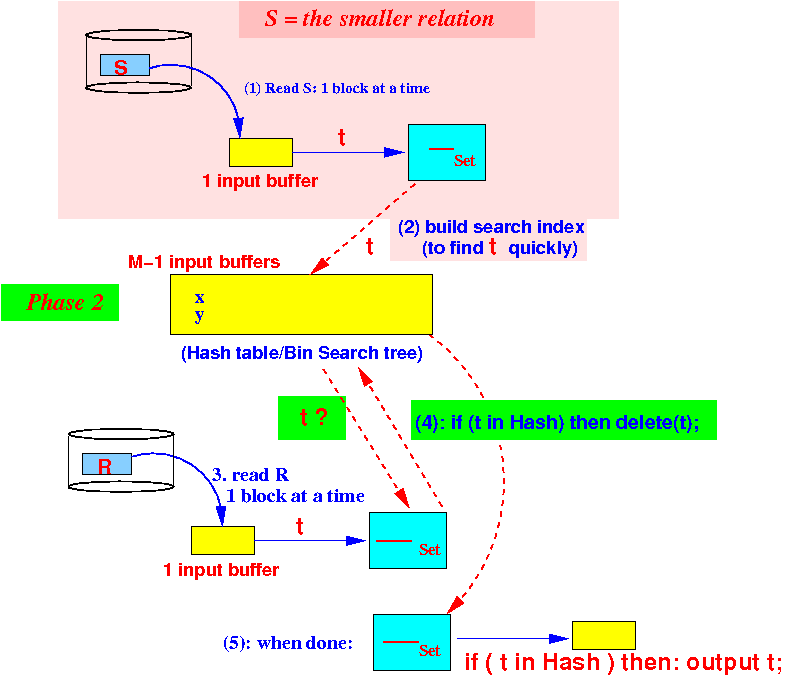
Use 1 buffer for input from R
We are still using M−1 buffers for the search structure in phase 2
- Phase 1:
partition the M buffers as
follows:
- Example:
S = {1, 2, 3, 4}; R = {2, 3, 5, 6, 7}; {2, 3, 5, 6, 7} − {1, 2, 3, 4} = {5, 6, 7}; ^^^^^^^^^^ Index this set
- One-pass algorithm:
initialize a search structure H on all attributes of γ; /* ============================================================ Phase 1: (same) Use 1 buffer and scan the SMALLER relation first. Build a search structure on the SMALLER relation The search structure contains a count for the search key ============================================================ */ while ( S has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { /* ===================================================== We need a search structure H to implement the test t ∈ H efficiently !!! We can use hash table or some bin. search tree ====================================================== */ insert t in H; } } /* =================================================== Now we know the elements in S =================================================== */ /* ============================================================ Phase 2: output tuples in R Use 1 buffer and scan the other relation. Use the search structure to "stop output" of common elements ============================================================ */ while ( R has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { /* ===================================================== We use search structure H to implement the test t ∈ H efficiently !!! We can use hash table or some bin. search tree ====================================================== */ if ( t ∉ H ) { Output t; // Tuple did not get subtracted ! } } }
Buffer utilization when there are M buffers available:
- Phase 1:
partition the M buffers as
follows:
Use 1 buffer for input from S
Use M−1 buffers for the search structure with a count(t) for each unique element in S
- Phase 2:
partition the M buffers as
follows:
Use 1 buffer for input from R
We are still using M−1 buffers for the search structure in phase 2
- Phase 1:
partition the M buffers as
follows:
- # disk I/O used:
- B(R) + B(S) --- if the relations R and S are clustered
- Memory requirement:
- M ≥ B(S) + 1 buffer