Slideshow:
Answering Partial Match queries using a
Partitioned Hashing index
Conclussion:

Answering Range queries using a
Partitioned Hashing index

Answering Range queries using a
Partitioned Hashing index
Translates to the following sets of values:

Answering Range queries using a
Partitioned Hashing index
Hash each pair of (Age, Salary) and find its bucket:
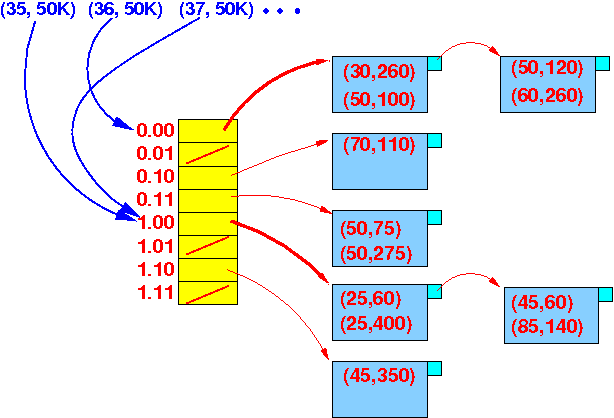
Note: there are duplicate bucket pointers ! (See: (35, 50K) and 37, 50K))
Answering Range queries using a
Partitioned Hashing index
Hash each pair of (Age, Salary) and find its bucket:
We must collect all the bucket pointers and remove duplicate bucket pointers before accessing the data !
Answering "Nearest Neighbor" queries using a Partitioned Hashing index

Answering "Nearest Neighbor" queries using a Partitioned Hashing index
- Why
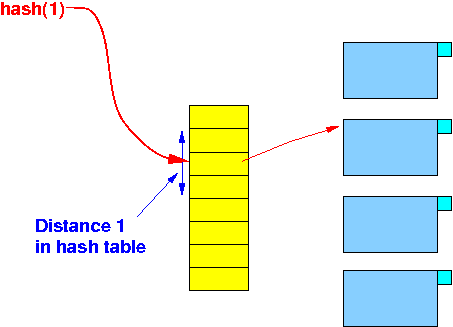
Suppose the search key 1 is hashed into some bucket:
Answering "Nearest Neighbor" queries using a Partitioned Hashing index
- Why
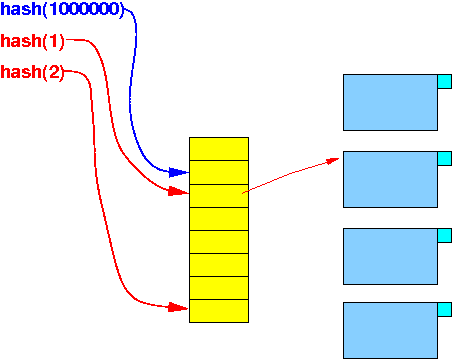
The nearest neighbor 2 can hashed far away while a far-away neighbor is hashed next to the key:
Answering "Where-am-I" queries using a Partitioned Hashing index
Grid index vs. Partitioned Hash index
Grid index can have poor occupancy rate in many grid buckets:
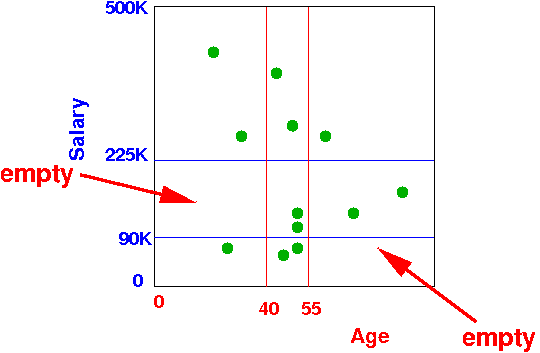
Many grid buckets can be empty
Partitioned hashing does not have this problem:

-
Partial Match queries
- The query specifies conditions on some dimensions but not on all dimensions
Example:
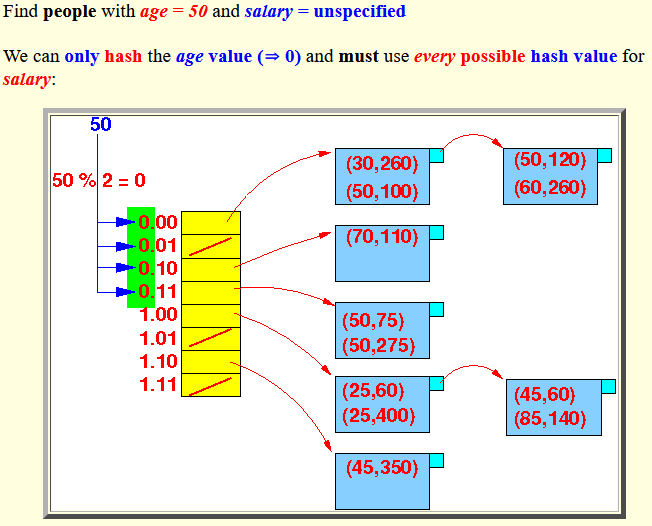
- Find people with
age = 50
and salary = unspecified
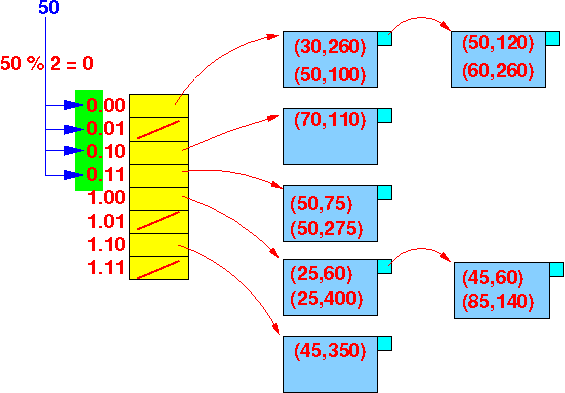
We can only hash the age value (50%2 ⇒ 0) and must use every possible hash value for salary:
Explanation:
- Age = 50 will hash
to the hash value:
Hash(age) = 0xx
- We start at bucket 000 and scan to bucket 011
- Age = 50 will hash
to the hash value:
Conclussion:
- Partial Hash index
can be used
to
reduce the
search space
The amount of search space that is reduced will depend on the sizes (# bits used) of the hash values
-
Range queries
- Find people such that:
35 ≤ age ≤ 50 ⇒ age = 35, 36, 37, ..., 50 50K ≤ salary ≤ 100 ⇒ salary = 50K, 51K, 52K, ..., 100K
- Solution:
- Hash
all values
inside
the specified range and
find their
bucket (block) pointers:
hash(35, 50K) --> block pointer 1 hash(36, 50K) --> block pointer 2 .... hash(50, 50K) And so on: (35, 55K) (36, 55K), .... (50, 55K) ... (35, 100K) (36, 100K), .... (50, 100K)Graphically:
Note: the block pointers can have duplicates !!!
- Collect all the
bucket pointers
(I.e.: eliminate any duplicate bucket (block) pointers !!!)
- Access all (unique) buckets (disk blocks)
- Hash
all values
inside
the specified range and
find their
bucket (block) pointers:
Comment:
- Hashing is in general not appropriate for range queries because a hash function does not preserve the "closeness" of values
- Find people such that:
-
Nearest neighbor queries:
- Hashing is
completely useless
for
nearest neighbor type
queries
Because:
- The is no notion of distance in the hash function !!!!
-
Example: find records that
with distance ≤ 1 to
search key = 1:
- We hash the
search key 1:
- However, we
cannot use the
distance in the
hash table to
locate
"nearby" objects (records)
because:
The value 2 is near the value 1, but may get hash very far away !!!
- Property of hashing:
- Closeness of bucket indexes has nothing to do with real distance between data points (because hashing computes a random number) !!!!
- We hash the
search key 1:
- Hashing is
completely useless
for
nearest neighbor type
queries
-
Where-am-I queries:
- Hashing is
also
not useful here either....
(Because hashing provide no information on distance)
- Hashing is
also
not useful here either....
- Advantage:
- Good hash functions will
randomize the
records:
- Partitioned hashing will achieve good occupancy rate per bucket
- Good hash functions will
randomize the
records:
- A major problem with
Grid
Index files is:
- Poor occupancy rate
at many grid buckets:
(Especially when you have 3 or more dimensions.
You will have many buckets that are empty !!!)
- Poor occupancy rate
at many grid buckets: