Slideshow:
The Zig-zag Join Algorithm
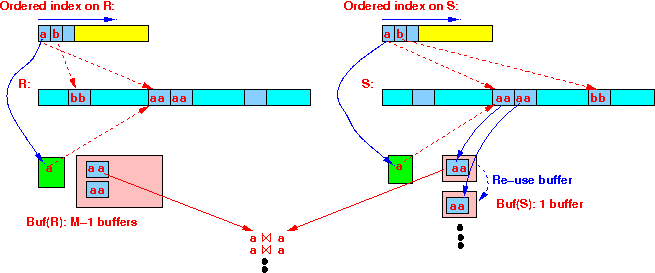
Read the index entries of R with the next smallest key r ; Read the index entries of S with the next smallest key s ; while ( R ≠ empty and S ≠ empty ) do { if ( search key r < search key s ) { Read the index entries of R with the next smallest key r ; (and repeat...) } else if ( search key s < search key r ) { Read the index entries of S with the next smallest key s ; (and repeat....) } if ( search key r = search key s ) { Use M-1 buffers to read in all tuples of R with search key r; Use 1 buffer to scan in all tuples of S with same join value; Join the tuples in Buf(R) and Buf(S): |
The Zig-zag Join Algorithm
- using
clustering index
The only difference when using a clustering index is accessing the tuples in the relations:
The joining tuples are located (packed) consecutively in disk blocks
The Zig-zag Join Algorithm
- Example
(using a clustering index)
Accessing the joining tuples when using a clustering index
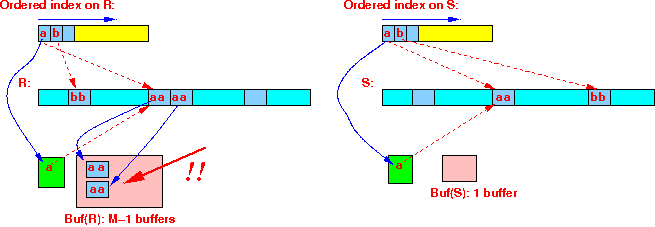
(r = a) = (s = a) → use M−1 buffers to store all the joining tuples from R
We will read each block in relation R once !
The Zig-zag Join Algorithm
- Example
(using a clustering index)
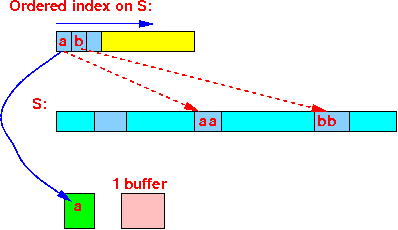
Accessing the joining tuples when using a clustering index
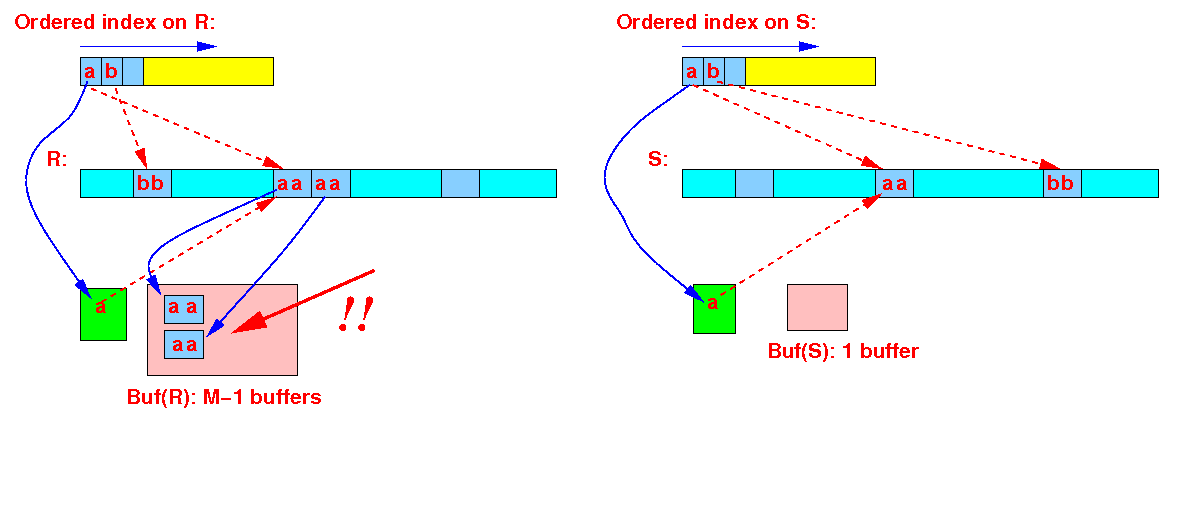
(r = a) = (s = a) → use 1 buffers to scan in all the joining tuples from S
We will read each block in relation S once !
IO cost of the
Zigzag Join Algorithm using a
clustering index
When a join value is found, we access R's tuples:

Worst case: we will access B(R) blocks (when every join value matches)
IO cost of the
Zigzag Join Algorithm using a
clustering index
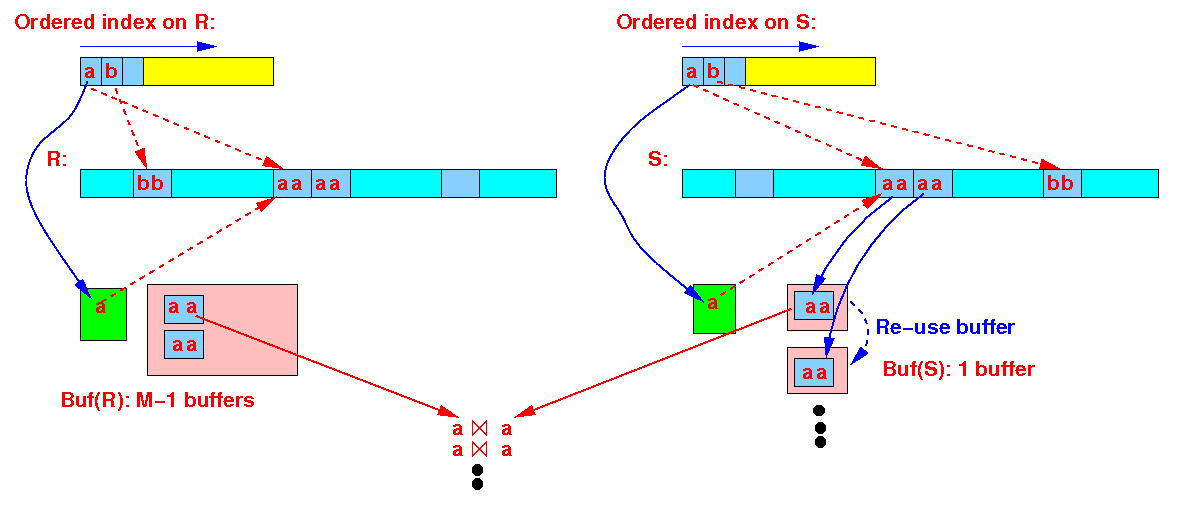
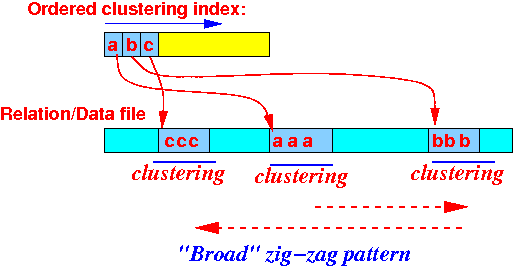
A graphical way to see that Zigzag Join will read R once (in a "zig-zag manner"):
Recall that the Zig-zag Join will access each tuple (at most) once !
IO cost of the
Zigzag Join Algorithm using a
clustering index
When a join value is found, we access S's tuples:

Worst case: we will access B(R) blocks (when every join value matches)
IO cost of the
Zigzag Join Algorithm using a
clustering index
Total IO cost:

- The zig-zag join
algorithm using a
clustering index
is
the same algorithm
as for
a non-clustering index:
The zig-zag join algorithm using a clustering index:
while ( R ≠ empty and S ≠ empty ) do { Read the index entries of R with the smallest key r :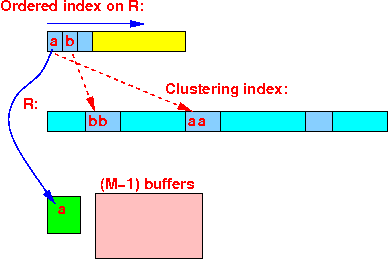 Read the index entries of S with the smallest key s :
Read the index entries of S with the smallest key s :
 if ( search key r < search key s )
{
discard all search keys r;
(and repeat...)
}
else if ( search key s < search key r )
{
discard all search keys s;
(and repeat....)
}
if ( search key s = search key r )
{
Read in all tuples of R with smallest search key (r) into M-1 buffers:
Use 1 buffer to read in all tuples of S with same join value;
Join the tuples in Buf(R) and Buf(S):
if ( search key r < search key s )
{
discard all search keys r;
(and repeat...)
}
else if ( search key s < search key r )
{
discard all search keys s;
(and repeat....)
}
if ( search key s = search key r )
{
Read in all tuples of R with smallest search key (r) into M-1 buffers:
Use 1 buffer to read in all tuples of S with same join value;
Join the tuples in Buf(R) and Buf(S):
 Join all tuples in Buf(R) and Buf(S);
After joining: discard search keys r and s in Buf(R) and Buf(S);
(Repeat....)
}
}
Join all tuples in Buf(R) and Buf(S);
After joining: discard search keys r and s in Buf(R) and Buf(S);
(Repeat....)
}
}
- The difference between
clustering and
non-clustering index is
the access pattern to
the data file (tuples):
- Using a clustering index,
we will read all joining
tuples
in
consecutive blocks :
- Using a clustering index,
we will read all joining
tuples
in
consecutive blocks :
- # disk accesses
to join R ⋈ S
using
a clustering index:
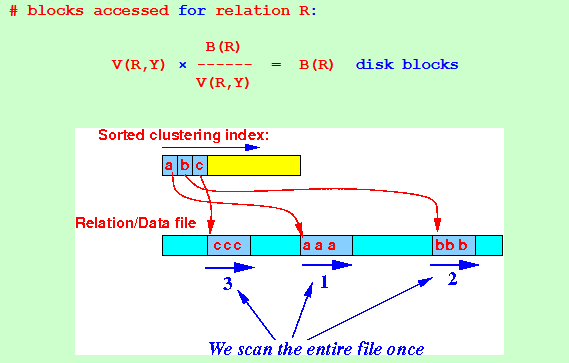
For relation R: 1. Read the ordered clustering index file Index files are relatively small So: we will ignore this cost 2. For each search key value: (index is clustering) B(R) read ------- data block to access the joining tuples V(R,Y) 3. # different search key values = V(R,Y) # blocks accessed for relation R: B(R) V(R,Y) × ------ = B(R) disk blocks V(R,Y)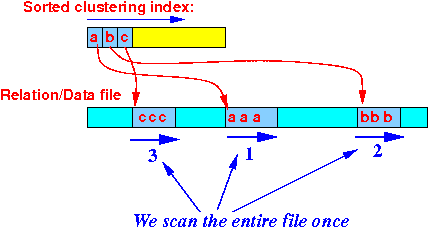
For relation S: 1. Read the ordered clustering index file Index files are relatively small So: we will ignore this cost 2. For each search key value: (index is clustering) B(S) read ------- data block to access the joining tuples V(S,Y) 3. # different search key values = V(S,Y) # blocks accessed for relation R: B(S) V(S,Y) × ------ = B(S) disk blocks V(S,Y)
Total # blocks accessed ~= B(R) + B(S)