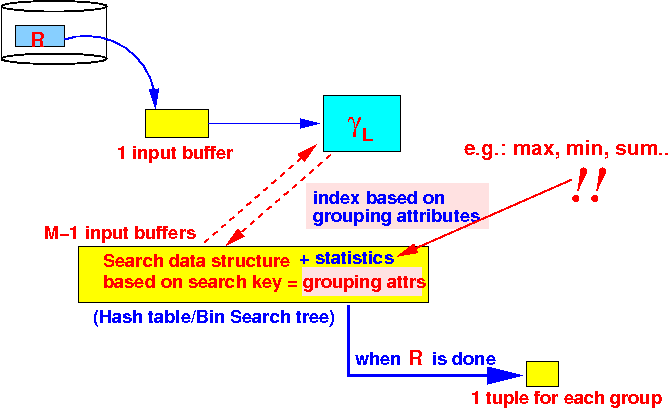
- One-pass algorithm:
initialize a search structure H on grouping attributes of γ; /* ========================================================= Process the statistics for each group ========================================================= */ while ( R has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { /* ===================================================== We need a search structure H to implement the test t ∈ H efficiently !!! We can use hash table or some bin. search tree ====================================================== */ if ( t ∈ H ) { Update the statistics for group(t); } else { insert t in H; Initialize the statistics for group(t); } } } /* ========================================================= Now we can output the aggregate function for each group ========================================================= */ for ( each group ∈ H ) { Output group search key + statistics; }
- Buffer utilization when
there are M buffers
available:
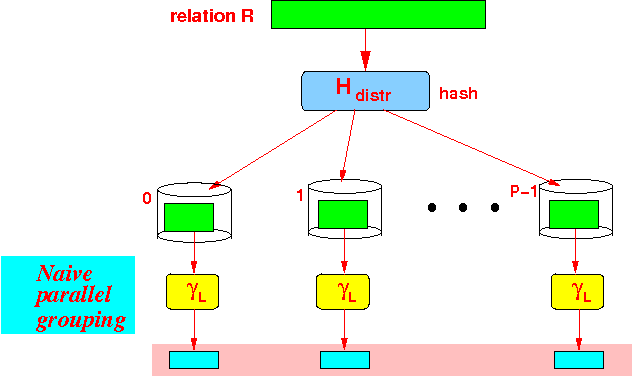
- Naive
parallel grouping γL:
- Each processor
executes the
uni-processor γL
locally on its
fragment
of relation R:
- Each processor
executes the
uni-processor γL
locally on its
fragment
of relation R:
- Why the
naive parallel algorithm
does not work:
- Tuples of the same group can be stored on different processors !!!!
Graphically:
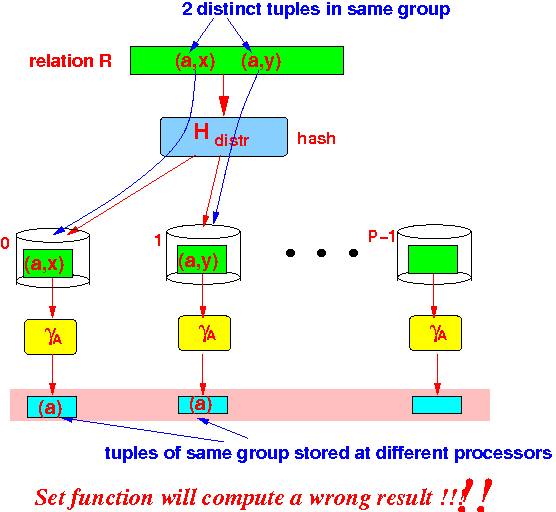
- Cause of the
problem:
- The hash distribution function
is based on the
entire tuple
- The grouping γL( R ) uses a different set of attributes !!!
Consequently:
- We must perform pre-processing (= re-hashing) so that the γL operator will operate correctly
- The hash distribution function
is based on the
entire tuple
- Fixing
parallel projection
algorithm:
- We must
first
re-distribute
(using hashing) the
tuples according to the
grouping attribute values:
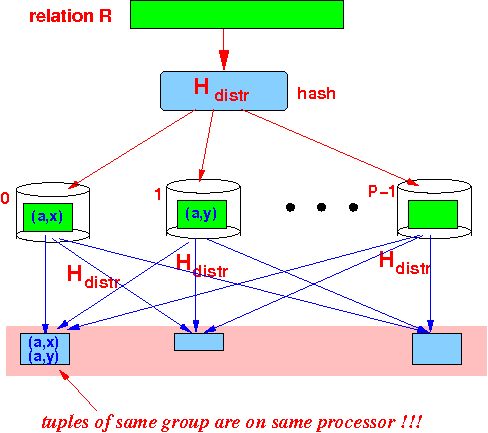
- Then:
each processor
executes the
(naive)
uni-processor
πattrs operation
locally on its
fragment
of relation R:
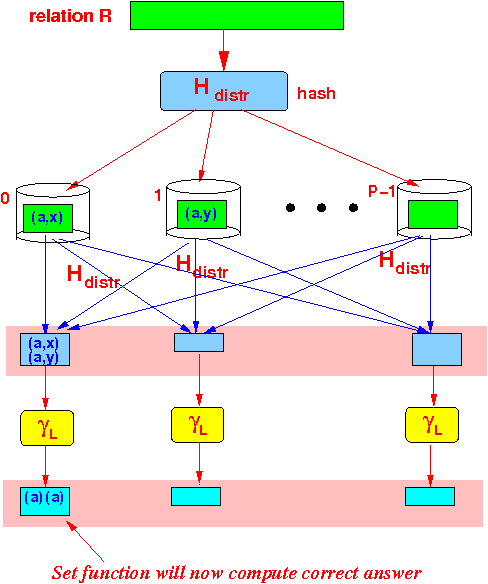
- We must
first
re-distribute
(using hashing) the
tuples according to the
grouping attribute values:
- Performance of the
parallel
γL:
- Re-distributing the
tuples:
- Read all
disk blocks
(to perform the hashing re-distribution):
B(R) blocks
- Transfer
P-1 ----- of the disk blocks Pto other nodes (assuming uniform distribution of project attribute values)
- Write the
re-distribued tuples
back to disk:
B(R) blocks(We assume the relation fragments are very large -- cannot not stored in memory)
- Read all
disk blocks
(to perform the hashing re-distribution):
- Performing
the uni-processor
grouping γL on
the tuples:
- Read the
tuples from
disk:
B(R) blocks
- Write the
(projection) tuples to
disk:
0 blocks
(Because the output of the last operation is not counted)
- Read the
tuples from
disk:
Graphically:
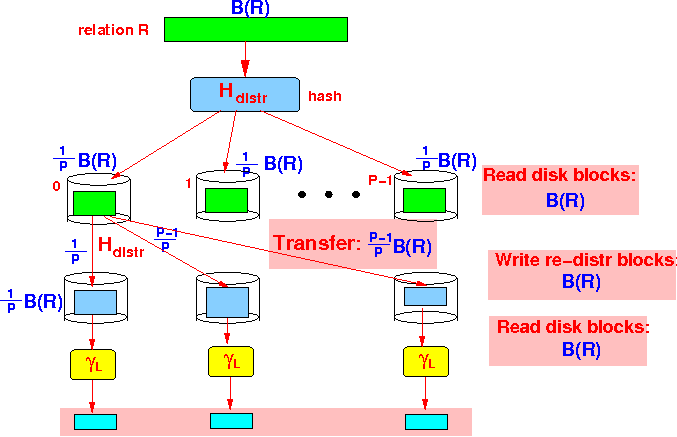
- Re-distributing the
tuples:
- Total amount of work:
Disk read/write: 3 B(R) blocks P-1 Transfered: ----- blocks P - Amount of work
per processor:
3 Disk read/write: --- B(R) blocks P P-1 Transfered: ----- blocks P2
(Transfer cost can be ignored in shared nothing processors)