Slideshow:
Intro to Iterators
|
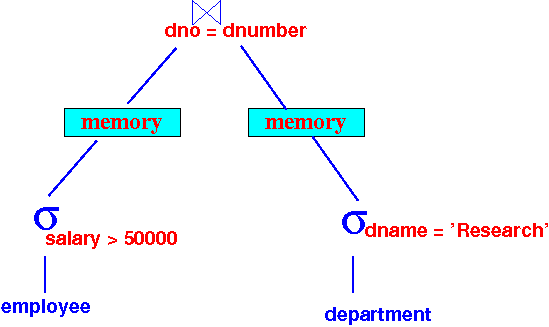
Prelude to Iterators: reader and writer processes
Prelude to Iterators: blocking
read/write operations

Anatomy of an operator
Cascading operators
Consider the operation of a serie of cascaded operators with blocking read/write operations:
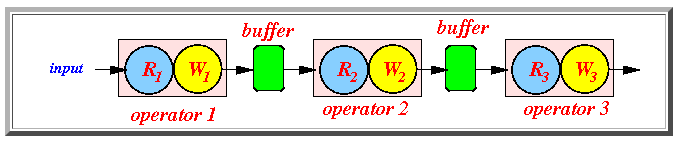
Claim: the operators will be synchronized through the buffers
Automatic blocking/unblocking behavior in operator chaining
Operator 1 is
paused waiting on its
input
Operator 2 is
paused waiting on
output from
operator 1
Operator 3 is
paused waiting on
output from
operator 2
Automatic blocking/unblocking behavior in operator chaining
Automatic blocking/unblocking behavior in operator chaining
Iterator: overview
What is an iterator:
- Iterator =
an (program) object that
enable a program to
traverse
a container
(such as a
list or a
set).
- For data processing,
an iterator must
provide (= implement) the following
methods (= functions):
- open( ):
prepare/initialize the
iterator to
perform its operation
(allocate resources)
- getNext( ):
returns the
next tuple
(or "NOT-FOUND" for
end)
- close( ): terminate the iterator (and de-allocate resources)
- open( ):
prepare/initialize the
iterator to
perform its operation
(allocate resources)
|
|
Iterator: open( ) operation

Iterator: getNext( ) operation

Iterator: close( ) operation

Example Iterator implementation:
Table-Scan operator
- the open( ) operation

Example Iterator implementation:
Table-Scan operator
- the getNext( ) operation

Example Iterator implementation:
Table-Scan operator
- the close( ) operation
Example Iterator implementation:
bag union (∪)
operation

R ∪bag S = bag of all tuples in R and S
Example Iterator implementation:
bag union (∪)
- the open( ) operation

Example Iterator implementation:
bag union (∪)
- the getNext( ) operation

Example Iterator implementation:
bag union (∪)
- the close( ) operation

Advantage of Iterators
- Readers and
writers:
- Reader =
a process that
reads data from
some source
- Writer = a process that outputs data
- Reader =
a process that
reads data from
some source
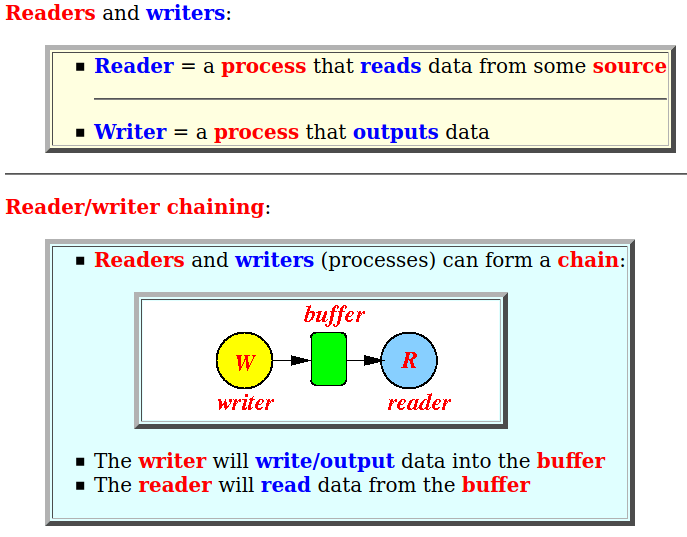
- Reader/writer chaining:
- Readers and
writers (processes)
can form a
chain:
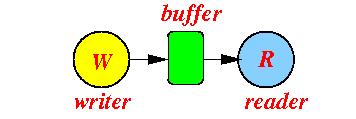
- The writer will write/output data into the buffer
- The reader will
read data from
the buffer
- Readers and
writers (processes)
can form a
chain:
- Important features of
input/output buffering:
- The writer (process) will
automatically block (=paused)
when the buffer is
full
(The writer is unblocked when the buffer space become available again)
- The reader (process) will
automatically block (=paused)
when the buffer is
empty
(The reader is unblocked when the buffer data become available again)
- The writer (process) will
automatically block (=paused)
when the buffer is
full
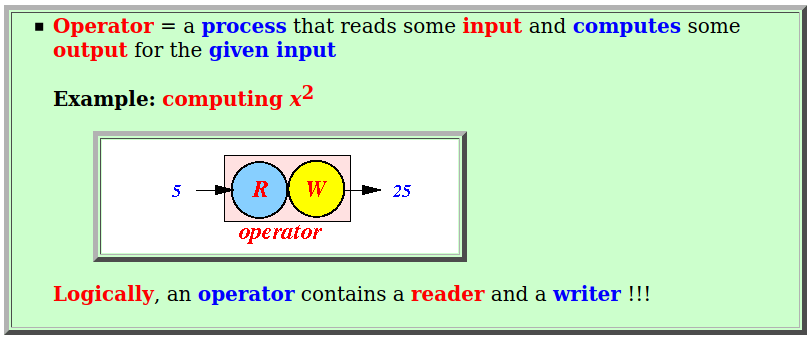
- Operator:
- Operator =
a process that
reads some input and
computes some
output for
the given input
Example: computing x2
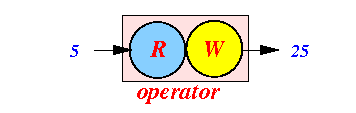
Logically, an operator contains a reader and a writer !!!
- Operator =
a process that
reads some input and
computes some
output for
the given input
- Passing result between
operators:

- The Automatic blocking
feature of
buffering can
control the
activity of
operators:
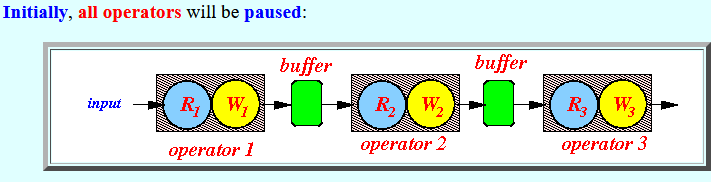
- Initially,
all operators will
be paused:

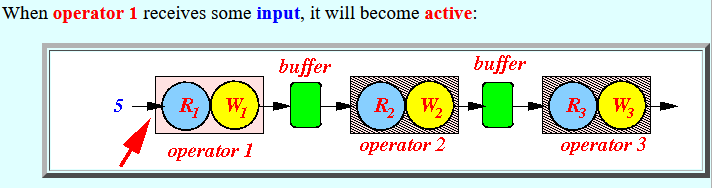
- When operator 1 receives
some input, it will
become active:

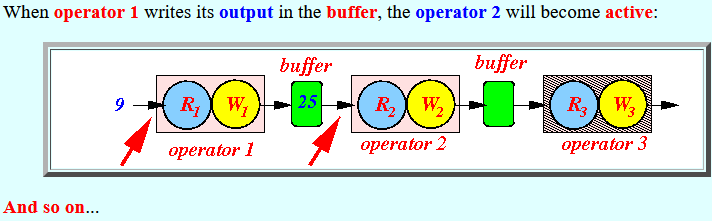
- When operator 1 writes
its output in the
buffer,
the operator 2 will
become active:

And so on...
- Initially,
all operators will
be paused:
- Iterator:
- Iterator =
an (program) object that provides
(at least) the following
3 methods (operations):
- open( ):
- This method
starts (prepares)
the process of
getting tuples
The method does not return any tuple
- The open() method will
initialize some
data structures (e.g., buffers)
needed to
get tuples
- If the
object is
a stored relation
(on disk),
the open() method will
open the
file of the relation
Otherwise (the iterator uses the result of other operators), the open() method will call the open() method of its argument(s)
- This method
starts (prepares)
the process of
getting tuples
- getNext( ):
- The getNext() method
returns the
next tuple
in the
object if
there are tuples remaining.
The getNext() method returns NOT-FOUND if the object has no more tuples.
- The getNext() method must update its data structure to allow subsequent tuple(s) to be retrieved
- The getNext() method
returns the
next tuple
in the
object if
there are tuples remaining.
- close( ):
- The close() method
cleans up the
object
De-allocate any memory used for data structures created by open()
- If the object is
a stored file,
the close() method will
close the opened file
Otherwise (the iterator uses the result of other operators), the close() method will call the close() method of its argument(s)
- The close() method
cleans up the
object
- open( ):
- Iterator =
an (program) object that provides
(at least) the following
3 methods (operations):
- The following pseudo code
are the
implementation
of the
Table-Scan
iterator
at the kernel level
I.e.:
- You perform the buffering of the disk blocks by yourself
- Open():
Open( ) { Open target relation R; b = allocate 1 block buffer space; b = read first block of R; // Prepare for getNext( ) t = address of first tuple in block b; // Prepare to return next tuple }
- getNext():
getNext( ) { /* ============================================================== Make sure t points to a valide tuple before proceeding ============================================================== */ if ( tuple t has passed the last tuple in block b ) { /* ------------------------------------------------- Re-position t to be the first tuple of next block ------------------------------------------------- */ Read the next block into b; if ( there is no next block ) { return NotFound; } else { t = first tuple in block b; } } /* =========================================== Here: t points to a valid next tuple =========================================== */ curr_t = t; // Save the return value increment t to the next tuple in block b; return curr_t; }
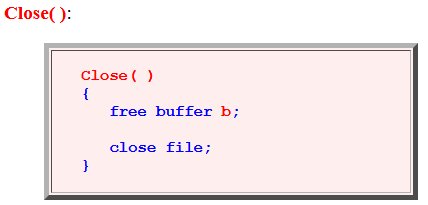
- Close( ):
Close( ) { free buffer b; close file; }
- Bag union:
- Bag union = a union operation that does not remove duplicates
The implementation of BagUnion will illustrate the pipelining effect :
- The tuples used by
BagUnion are
obtained by
calling the
getNext( ) method
in ScanTable
- The effect is:
- The tuples are passed from one operation to another operation through main memory (buffer)
- Open( ):
ScanTable R, S = input relations to BagUnion Open( ) { R.Open(); // This will call the Open() method in ScanTable !!! CurrRel = R; }
- getNext():
getNext() { if ( currRel == R ) { t = R.getNext(); // Call ScanTable to get next tuple if ( t ≠ NotFound ) { /* ------------------------------ We read a valid tuple from R ------------------------------ */ return t; } else { /* =========================== R is done, we read S next =========================== */ S.Open(); // Call ScanTable's Open() currRel = S; // Make this if-statement stop executing } } /* ============================================= We will only reach here if R is exhausted... ============================================= */ return S.getNext(); }
- Close( ):
Close( ) { R.Close( ); S.Close( ); }
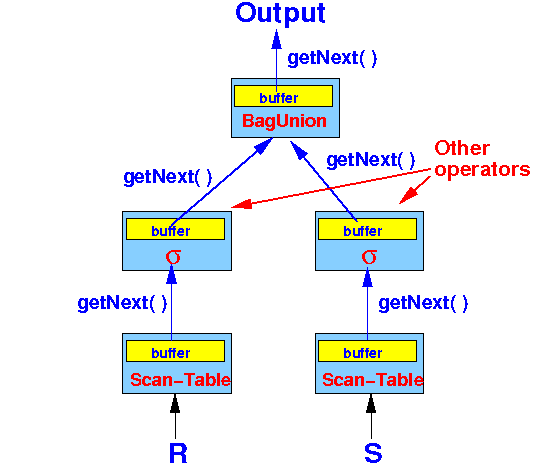
- We can see the effect of
a pipeline of
iterators in the
previous example:
- BagUnion uses the following
2 input arguments to
compute the union:
R S
- The tuples of the relations
are fetched by
an iterator ScanTable
- The iterator ScanTable passes the tuples of a relation to BagUnion through a memory buffer
- BagUnion uses the following
2 input arguments to
compute the union:
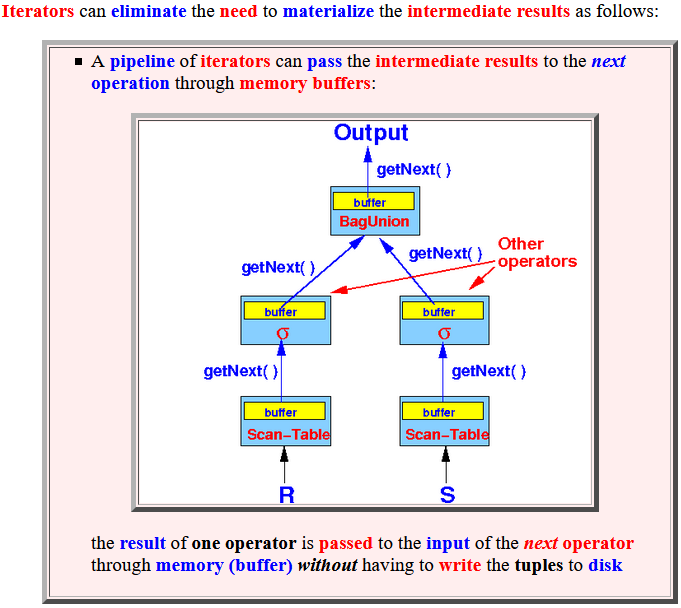
- Iterators
can eliminate
the need to
materialize
the intermediate results
as follows:
- A pipeline of
iterators can
pass the
intermediate results
to the next operation
through memory buffers:
the result of one operator is passed to the input of the next operator through memory (buffer) without having to write the tuples to disk
- A pipeline of
iterators can
pass the
intermediate results
to the next operation
through memory buffers: