Slideshow:
Processing a selection
(σA=c(R))
using
an non-clustering index
How to process σA=c (R) using an non-clustering index on attribute A:
IO cost of
selection
(σA=c(R))
using
a non-clustering index
-
reading the
index file
# disk IOs to read the index file:

IO cost of
selection
(σA=c(R))
using
a non-clustering index
-
reading the
data file
# disk IOs to read the data file:
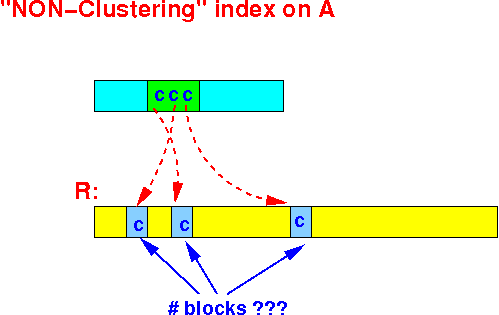
How many disk blocks do we need to read ???
IO cost of
selection
(σA=c(R))
using
a non-clustering index
-
reading the
data file
Estimating the # disk IOs needed to read the data file:
Assumption: each tuple is stored in different disk block (worst case)
# disk block with tuples A=c ~= T(R)/V(R,A) blocks
IO cost of
selection
(σA=c(R))
using
a non-clustering index

IO cost of
selection
(σA=c(R))
using
a non-clustering index
-
special case:
key attribute

- If index A on
R is a
NON-clustering index,
we process
σA=c(R)as follows:
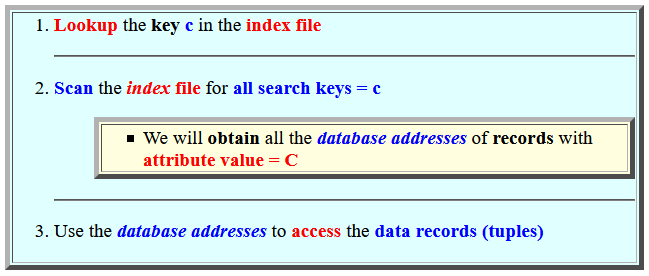
- Lookup
the key c in the
index file
- Scan the
index file
for all search keys = c
- We will obtain all the database addresses of records with attribute value = C
- Use the database addresses
to access the
data records (tuples)
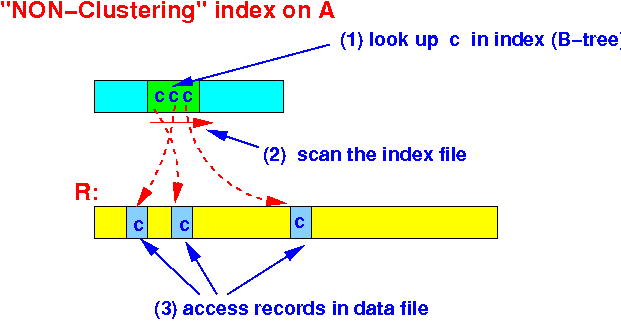
- Lookup
the key c in the
index file
- Graphically:
- # disk IOs:
- # disk IOs to
read the
index file:
- Because the index file is much smaller than the data file, we can ignore the disk IOs used to access the index
# disk IOs to read the data (relation) file = negligible
- # disk IOs to
read the
data (relation) file:
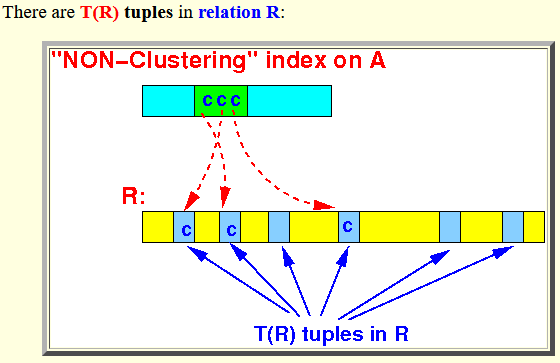
- We access
all records with
one specific value
of attribute value c:
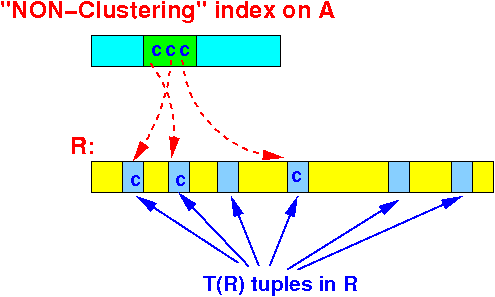
- There are T(R) tuples in
relation R:
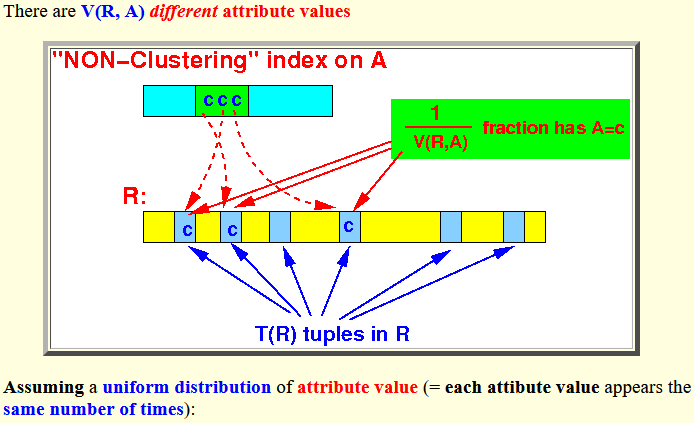
- There are V(R, A)
different attribute values
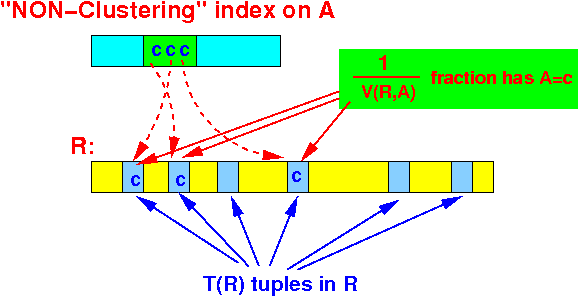
Assuming a uniform distribution of attribute value (= each attibute value appears the same number of times):
Total # tuples in R = T(R) # different "groups" of A = V(R,A) 1 # tuples per "group" = ------ T(R) V(R(A)
Assuming that each tuple is in a different block: 1 Total # blocks read for σA=c(R) = ------ T(R) blocks V(R,A)
- We access
all records with
one specific value
of attribute value c:
- # disk IOs to
read the
index file:
- Summary:
Non-clustering index: 1 Select cost for R with (A=c) = ------ T(R) blocks V(R,A)(plus a negligible number of disk IOs for accessing the index file)
- Note:
- The cost to execute
σA=c(R)
without an
index is:
Cost of σA=c(R) without index = T(R) blocksbecause we must access all of the T(R) tuples (and we assume different tuples are stored in different blocks) !!!
- The cost to execute
σA=c(R)
without an
index is:
- Special case:
(key)
- If A is a
key of the
relation R, then:
# Disk I/O = 1 block !!!because there is only 1 tuple with that specific attribute value !!!
- If A is a
key of the
relation R, then: