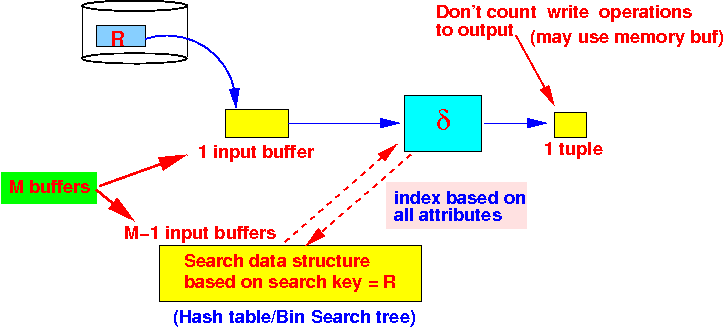
- One-pass algorithm:
initialize a search structure H on all attributes of R; while ( R has more data blocks ) { read 1 data block in buffer b; for ( each tuple t ∈ b ) { /* ===================================================== We need a search structure H to implement the test t ∈ H efficiently !!! We can use hash table or some bin. search tree ====================================================== */ if ( t ∈ H ) { discard t // duplicate } else { insert t in H; // Help find duplicates move t to output // This is the first occurence } } }Buffer utilization when there are M buffers available:
- Parallel algorithm for
δ(R):
- Each processor executes
the single-processor δ( )
locally on its
fragment of
relation R:
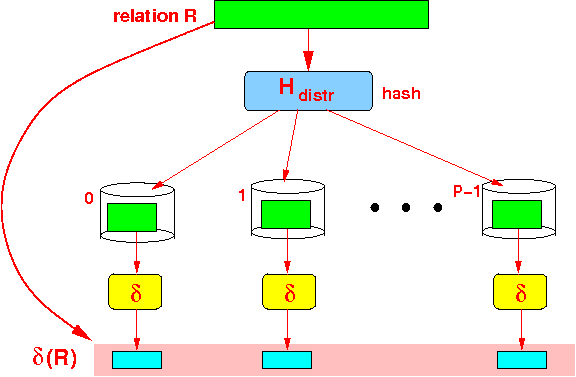
Result:
- The collection (bag) of the output of (at) each processor is the output of δ(R)
- Each processor executes
the single-processor δ( )
locally on its
fragment of
relation R:
- Duplicates can be
eliminated
locally
because:
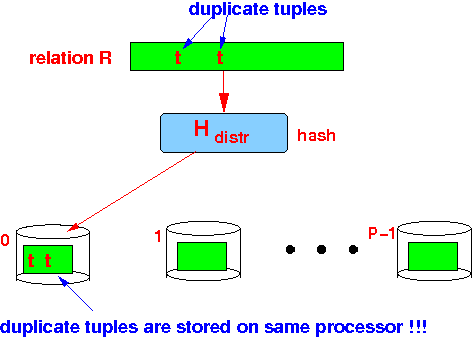
duplicate tuples will always stored at the same processor !!!
- Performance
of the parallel
δ(R):
- Distribution of the
relation R:
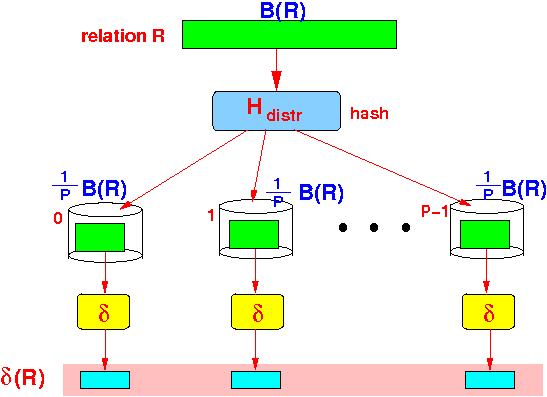
- Each processor will
perform:
1 --- B(R) disk block read operations P
Therefore:
- The parallel
δ(R)
operation will
- complete in 1/P of the time
- Distribution of the
relation R: