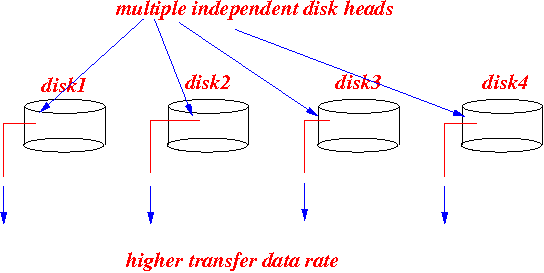
General approaches to speed up
access
to data stored on disks
-
Techniques
(and tricks) to
speed up
disk access
operations:
- Placement
(opportunistic)
- Striping
(space/parallellism)
- Scheduling
(opportunistic - analogy:
elevator)
- Pre-fetching
(time-overlap/parallellism)
|
- We will
briefly
discuss
each technique in this
webpage
|
Placement
of sectors
- A disk block is the
unit of
a disk access
operation
- A read/write operation to
disk will
read/write
1 disk block
|
- A disk block consists of
N sectors
-
Placement of
sectors in a
disk block:
- On same
track
- Sectors
phyically
follows
each other on track
|
- Reading/writing the
first
sector of a
disk block is
typically
slow
due to:
-
High
seek time
-
High
rotational delay
|
- Reading/writing
subsequent
sectors of a
disk block is
fast
because:
-
0 msec
seek time
-
Low
rotational delay
|
|
Striping:
spread a file blocks over
multiple disks
- Non-striped and
striped
storage
strategy:
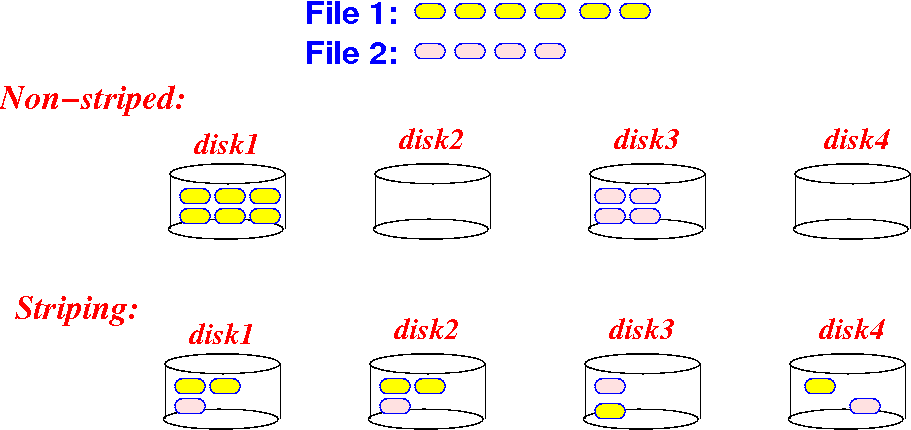
Striping:
- The disk blocks of
data files are
spread
over all
disks
|
|
Striping:
spread a file blocks over
multiple disks
Commonly used
scheduling discipline:
First Come First Server (FCFS)
- FIFC:
the requests
are served
in the order
they were received
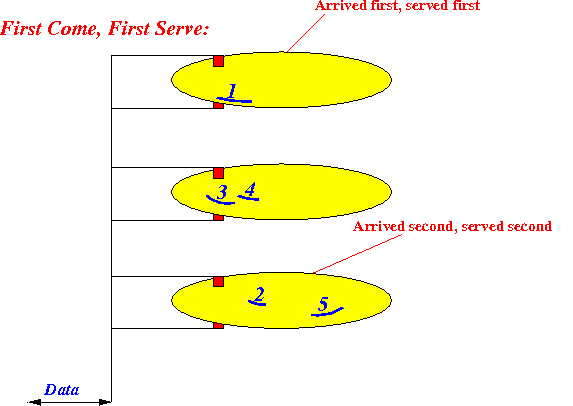
|
Strength and
weakness of the
First Come First Server (FCFS) scheduling
Efficient
Disk Scheduling
Algorithm: the
Elevator Algorithm
- Operation of an
idle
elevator:
- When someone on
floor k presses the
elevator request
button:
- Make a
request to
stop at
floor k
- Move to
floor k
|
|
- Operation of an
active
elevator:
- When someone on
floor k presses the
elevator request
button:
- Add a
request to
stop at
floor k
|
- When the
elevator arrives
on floor k:
-
All requests
for floor k are
serviced before
moving to
next floor!
|
|
|
❮
❯