Slideshow:
Tweeking the
performance of the Zig-zag join algorithm
Observation:
Tweeking the
performance of the Zig-zag join algorithm
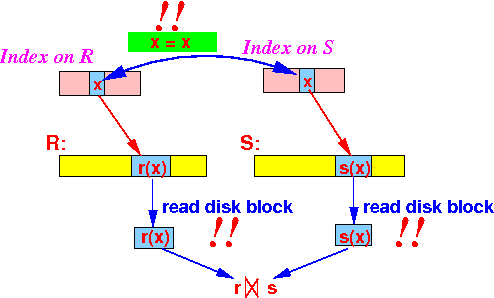
Tweek: We will only access the data block (containing the join tuple) if they have the same search key values:
|
Assumption:
accessing the
(smaller) index file
requires negligible
# disk IO operations
(We will ignore these operations in the total # disk IOs)
The Zig-zag Join Algorithm
Read the index entries of R with the next smallest key r ; Read the index entries of S with the next smallest key s ; while ( R ≠ empty and S ≠ empty ) do { if ( search key r < search key s ) { Read the index entries of R with the next smallest key r ; (and repeat...) } else if ( search key s < search key r ) { Read the index entries of S with the next smallest key s ; (and repeat....) } if ( search key r = search key s ) { Use M-1 buffers to read in all tuples of R with search key r; Use 1 buffer to scan in all tuples of S with same join value; Join the tuples in Buf(R) and Buf(S): |
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
(r = 1) < (s = 2) → read the next smallest join value from R's index file
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
(r = 3) > (s = 2) → read the next smallest join value from S's index file
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
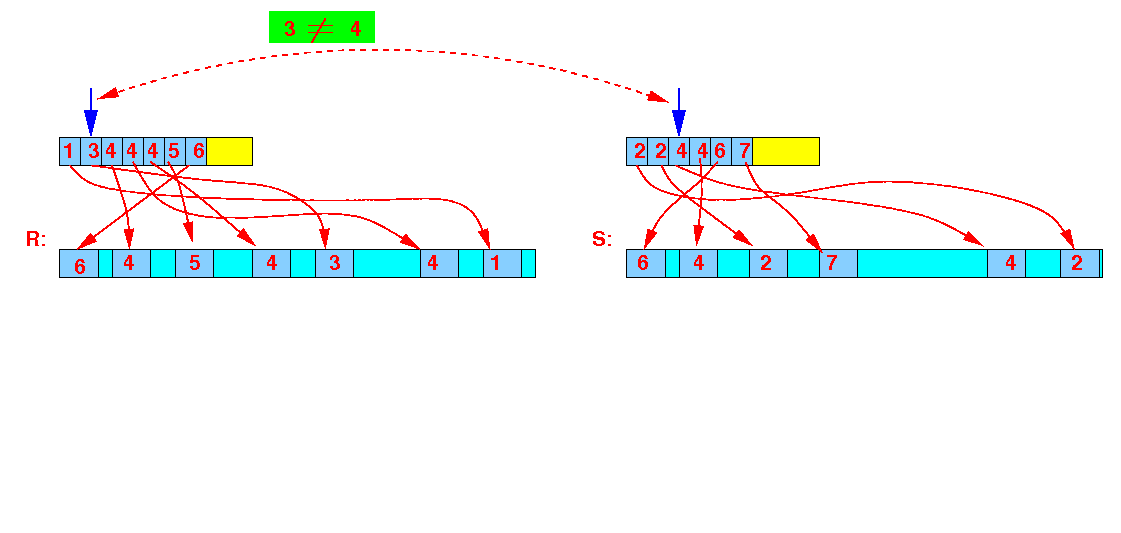
(r = 3) > (s = 4) → read the next smallest join value from R's index file
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
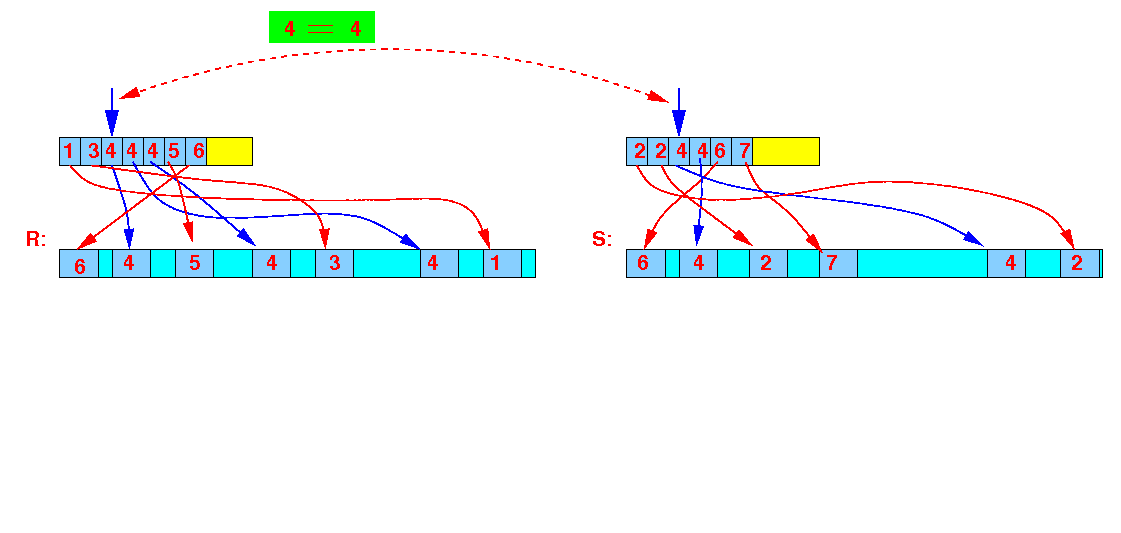
(r = 4) = (s = 4) → join the tuples from relation R and S !!
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
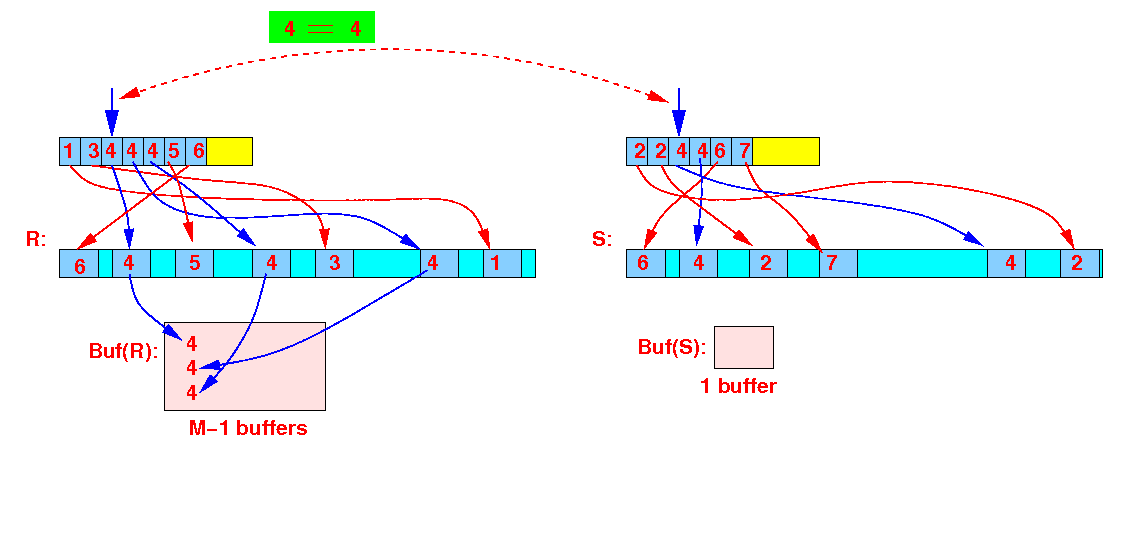
(r = 4) = (s = 4) → use M−1 buffers to store all the joining tuples from R
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
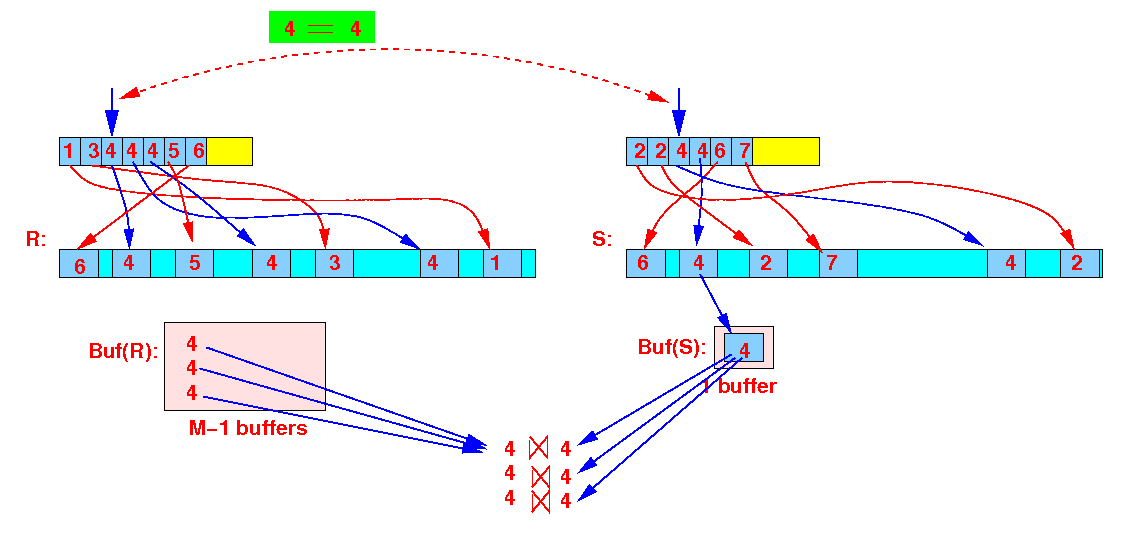
(r = 4) = (s = 4) → use 1 buffers to scan in all the joining tuples from S
The Zig-zag Join Algorithm
- Example
(using a non-clustering index)
Read the index files and find next smallest join values:
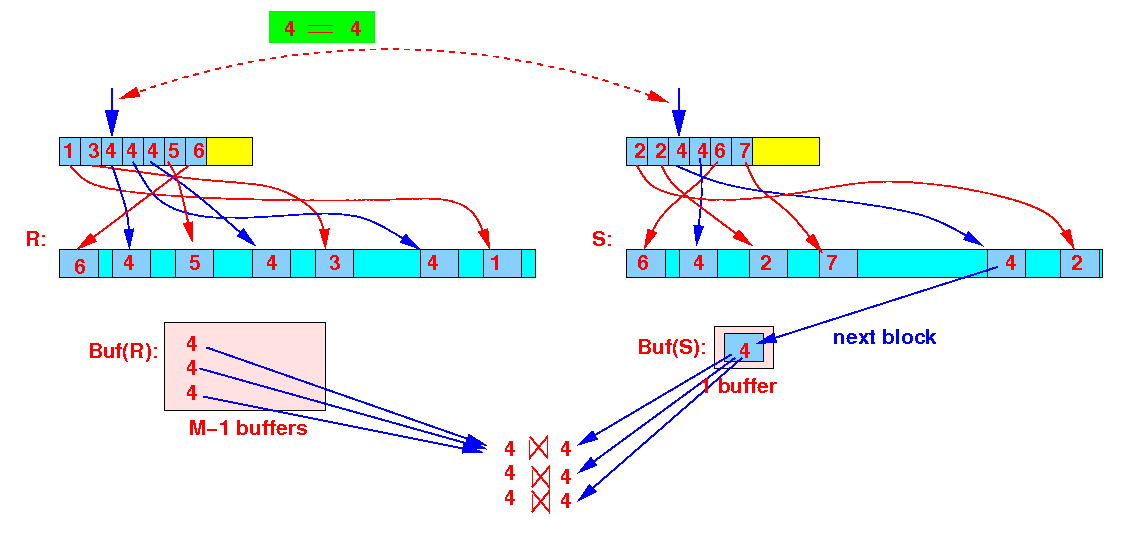
Notice that: you must use 1 buffer to access data blocks from S
IO cost of the
Zigzag Join Algorithm using a
non-clustering index
Observation:
IO cost of the
Zigzag Join Algorithm using a
non-clustering index
When a join value is found, we access R's tuples:

Worst case: we will access T(R) blocks (if accessing 1 tuple result in 1 disk IO operation)
IO cost of the
Zigzag Join Algorithm using a
non-clustering index
When a join value is found, we access S's tuples:

Worst case: we will access T(S) blocks (if accessing 1 tuple result in 1 disk IO operation)
Total IO cost:
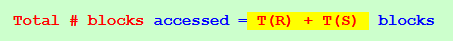
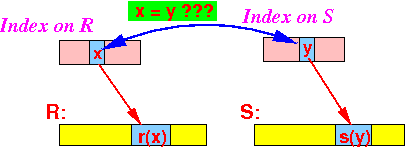
- Observation:
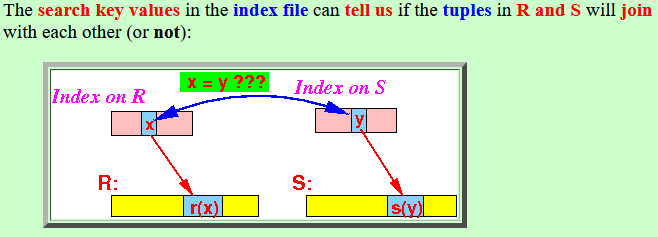
- The search key values
in the index file
can tell us if
the tuples in
R and S will
join with each other
(or not):
- Therefore:
- We will only
access the
data block
(containing the join tuple)
if they have the
same search key values:
- We will only
access the
data block
(containing the join tuple)
if they have the
same search key values:
- The search key values
in the index file
can tell us if
the tuples in
R and S will
join with each other
(or not):
- The zig-zag join algorithm
(illustrated
using a non-clustering index):
Read the index entries of R with the next smallest key r :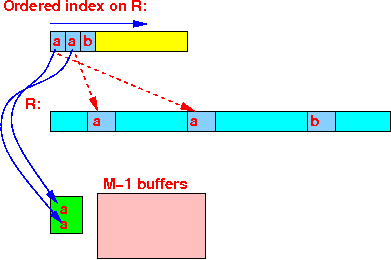 Read the index entries of S with the next smallest key s :
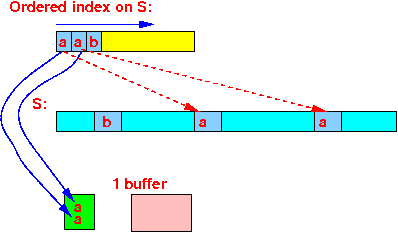
Read the index entries of S with the next smallest key s :
 while ( R ≠ empty and S ≠ empty ) do
{
if ( search key r < search key s )
{
Discard all search keys r;
Read the index entries of R with the next smallest key r ;
(and repeat...)
}
else if ( search key s < search key r )
{
Discard all search keys s;
Read the index entries of S with the next smallest key s ;
(and repeat....)
}
if ( search key r = search key s )
{
Use M-1 buffers to read in all tuples of R with search key r:
while ( R ≠ empty and S ≠ empty ) do
{
if ( search key r < search key s )
{
Discard all search keys r;
Read the index entries of R with the next smallest key r ;
(and repeat...)
}
else if ( search key s < search key r )
{
Discard all search keys s;
Read the index entries of S with the next smallest key s ;
(and repeat....)
}
if ( search key r = search key s )
{
Use M-1 buffers to read in all tuples of R with search key r:
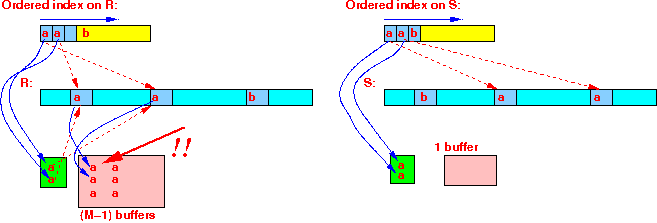 Use 1 buffer to scan in all tuples of S with same join value;
Join the tuples in Buf(R) and Buf(S):
Use 1 buffer to scan in all tuples of S with same join value;
Join the tuples in Buf(R) and Buf(S):
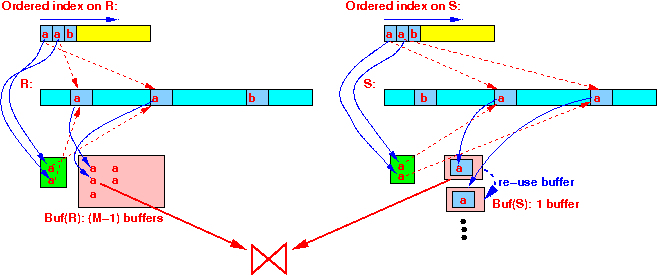 After joining: discard search keys r and s;
Read the index entries of R with the next smallest key r ;
Read the index entries of S with the next smallest key s ;
(Repeat....)
}
}
After joining: discard search keys r and s;
Read the index entries of R with the next smallest key r ;
Read the index entries of S with the next smallest key s ;
(Repeat....)
}
}
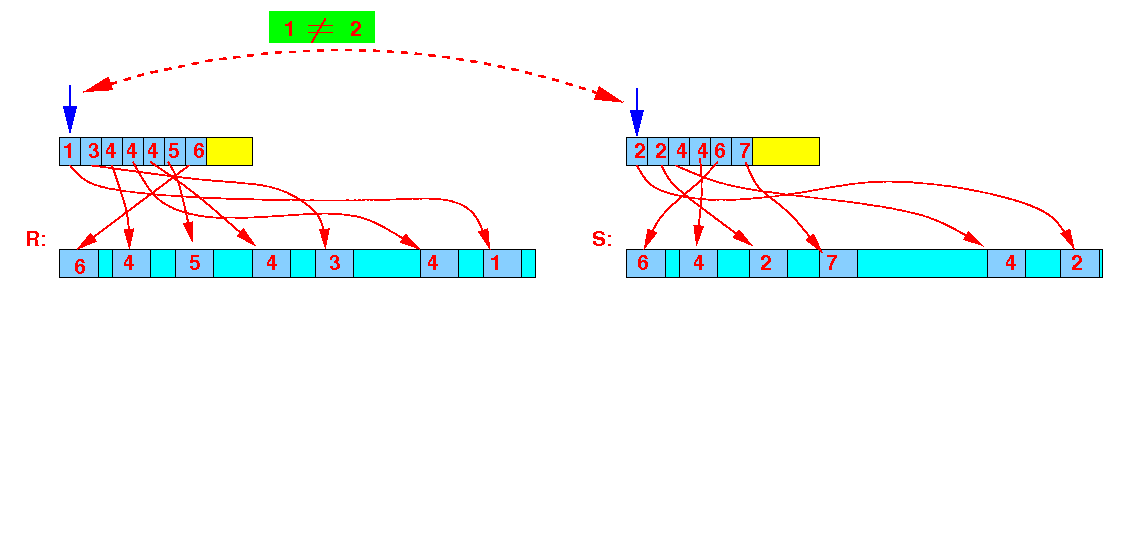
- Example:
- Step 1:
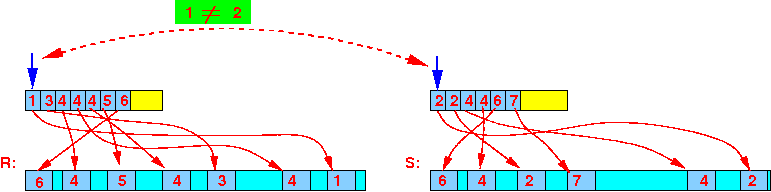
1 ≠ 2 ⇒ advance R
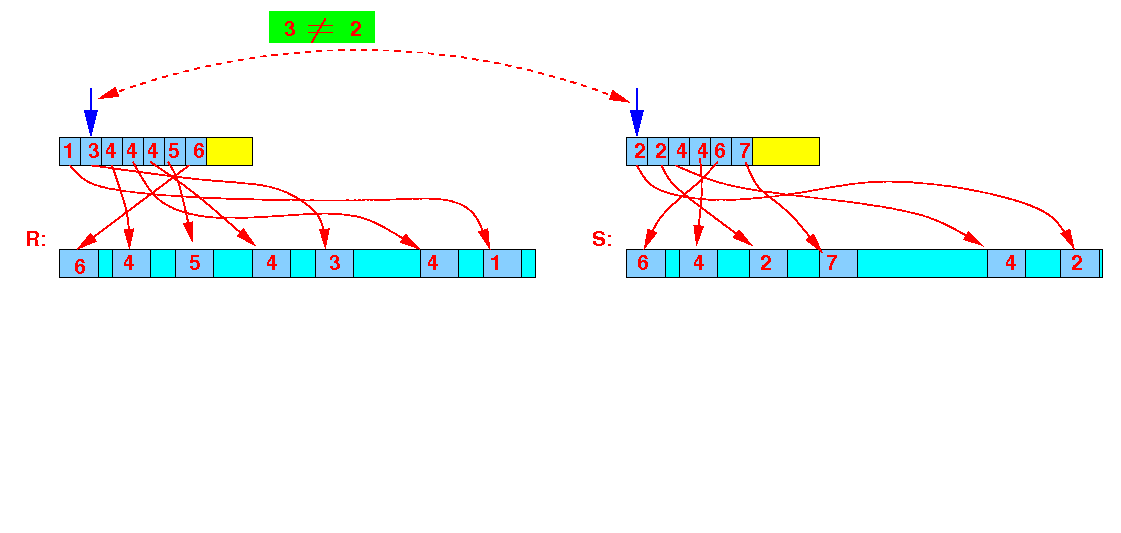
- Step 2:
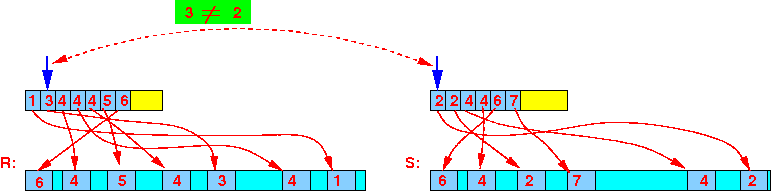
3 ≠ 2 ⇒ advance S
- Step 3:
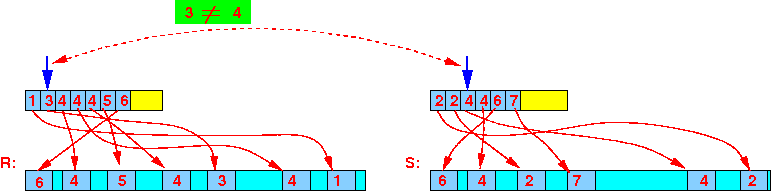
3 ≠ 4 ⇒ advance R
- Step 4:
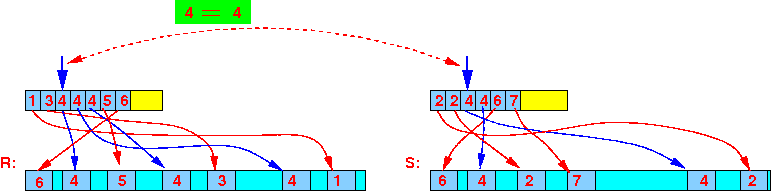
4 == 4:
- Read
all tuples
with this search key from
R
into
(M-1) memory buffers:
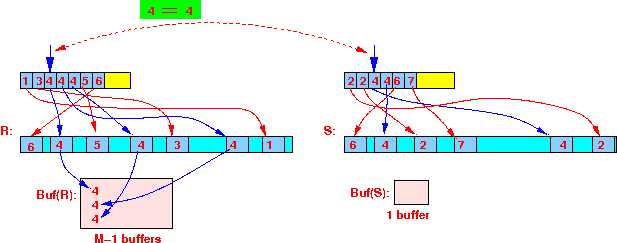
- Then join the
tuples from S:
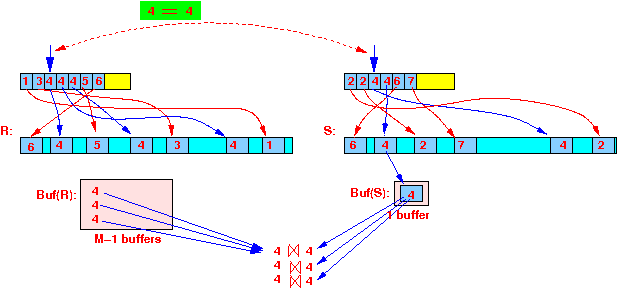
one tuple at a time:
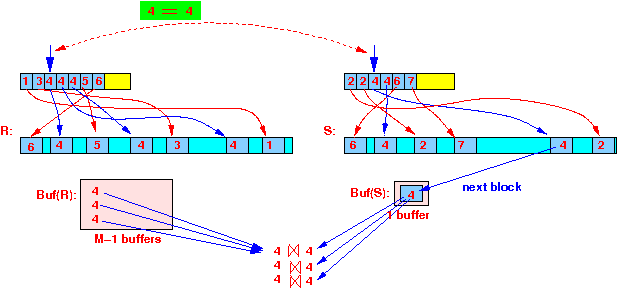
- Read
all tuples
with this search key from
R
into
(M-1) memory buffers:
- And so on
- Step 1:
- Notice:
- The data tuples
are not accessed until
there is a match in
search (index) keys !!!
- Index file entries are usually smaller than data records !!!
- Data records are
not accessed
when the
search keys
do
not
match:
Data records are only accessed when there is a match in the search (index) keys:
- The data tuples
are not accessed until
there is a match in
search (index) keys !!!
- Observation about the
zig-zag join algorithm:
- The zig-zag join algorithm will
access
each tuple at most
once
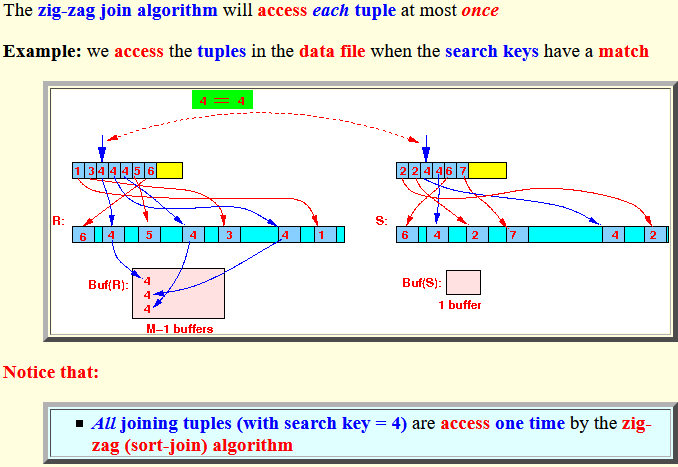
Example: we access the tuples in the data file when the search keys have a match
Notice that:
- All joining tuples (with search key = 4) are access one time by the zig-zag (sort-join) algorithm
- The zig-zag join algorithm will
access
each tuple at most
once
- # disk accesses to
read
all tuples
(in sorted order)
in a relation using
a non-clustering index:
For relation R: 1. Read the ordered non-clustering index file Index files are relatively small So: we will ignore this cost 2. For each search key: (index is non-clustering) read 1 tuple (= 1 block) to read the data record (tuple) # tuples in R = T(R) # blocks accessed for R = T(R) blocks
For relation S: 1. Read the ordered non-clustering index file Index files are relatively small So: we will ignore this cost 2. For each search key: (index is non-clustering) read 1 tuple (= 1 block) to read the data record (tuple) # tuples in S = T(S) # blocks accessed for S = T(S) blocks
Total # blocks accessed = T(R) + T(S) blocks (worst case - some records may not be read !)
- The algorithm is
called
zig-zag join because:
- We search for
matching key values
alternatingly between
the 2 relations
Example:
- Initially:
We search in R for the next matching value
- Then:
We search in S for the next matching value
- Then:
We search in R for the next matching value
And so on...
- Initially:
- We search for
matching key values
alternatingly between
the 2 relations