Slideshow:
The "traditional" way to execute query plans (low memory systems)

A better way to execute query plans

Constraint/caveat for using
pipelining
- Naive way: materialization
- Evaluate the
query plan (tree)
from
bottom-up
- Each operation would
store its
result on
disk
(= materialized as a relation)
- Subsequent operators read the result of its predecessor from disk
- Evaluate the
query plan (tree)
from
bottom-up
- Note:
- It was not so long ago that
materialization
was the only way to
execute a query....
(because computer memory used to be very expensive and a computer has very little main memory....)
- It was not so long ago that
materialization
was the only way to
execute a query....
- More efficient way: Pipelining
- Interleave the
execution of
all
operators
in the query plan
- All operators are active unless they are blocked waiting for input data
- Tuples produced by an operator is passed directly to its successor (consumer) (without storing the data on disk)
- Interleave the
execution of
all
operators
in the query plan
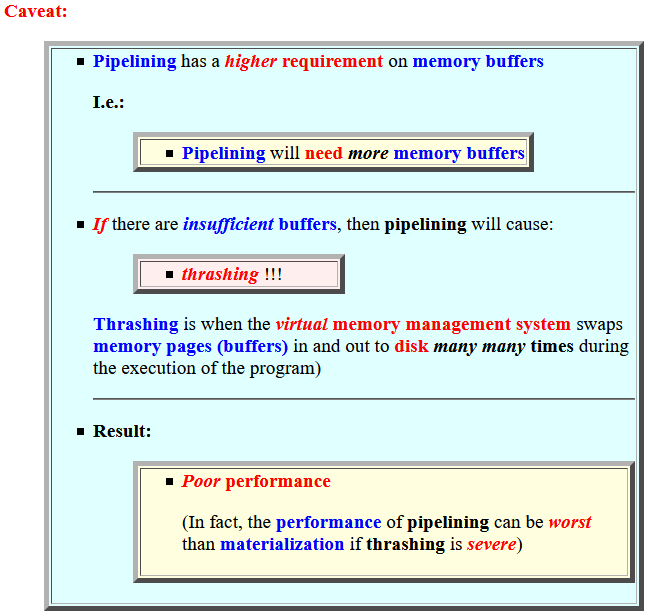
- Caveat:
- Pipelining has
a higher requirement
on memory buffers
I.e.:
- Pipelining will need more memory buffers
- If there are
insufficient buffers,
then pipelining will cause:
- thrashing !!!
Thrashing is when the virtual memory management system swaps memory pages (buffers) in and out to disk many many times during the execution of the program)
- Result:
- Poor performance
(In fact, the performance of pipelining can be worst than materialization if thrashing is severe)
- Poor performance
- Pipelining has
a higher requirement
on memory buffers