Slideshow:
The join (⋈) operator
(Cannot build a search structure because there is not enough memory)
Pre-requisite for using the
IO-efficient TPMMS-based join algorithm

The IO-efficient
2-pass TPMMS based join
(⋈) algorithm
- Pass 1
(Graphically explained in next slide)
The IO-efficient
2-pass TPMMS based join
(⋈) algorithm
- Pass 1
Use M buffers and sort the relation R and S into chunks of (sorted) M blocks:
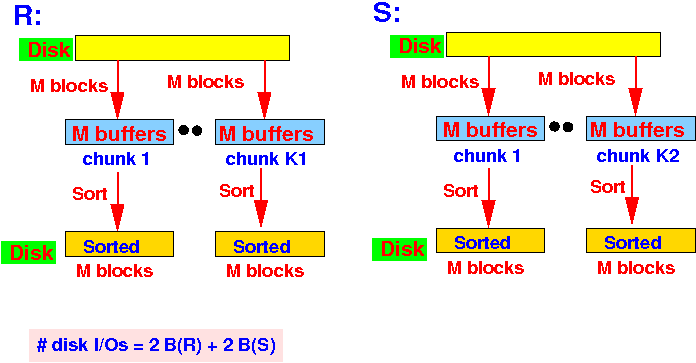
IO cost for pass 1 = 2 B(R) + 2 B(S)
The IO-efficient
2-pass TPMMS based join
(⋈) algorithm
- Pass 2
Pass 2:
(Graphically explained in next slide)
The IO-efficient
2-pass TPMMS based join
(⋈) algorithm
- Pass 2
Pass 2:

You must be able to store all joining tuples from R and S in (a few) program variables
The IO-efficient
2-pass TPMMS based join
(⋈) algorithm
- Example
- Pass 1
Pass 1: read chunks of M blocks from relations R and S and sort:
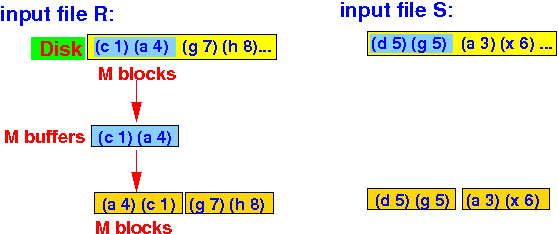
Write the sorted chunks (each chunk is M blocks) to disk
The IO-efficient
2-pass TPMMS based join
(⋈) algorithm
- Example
- Pass 2
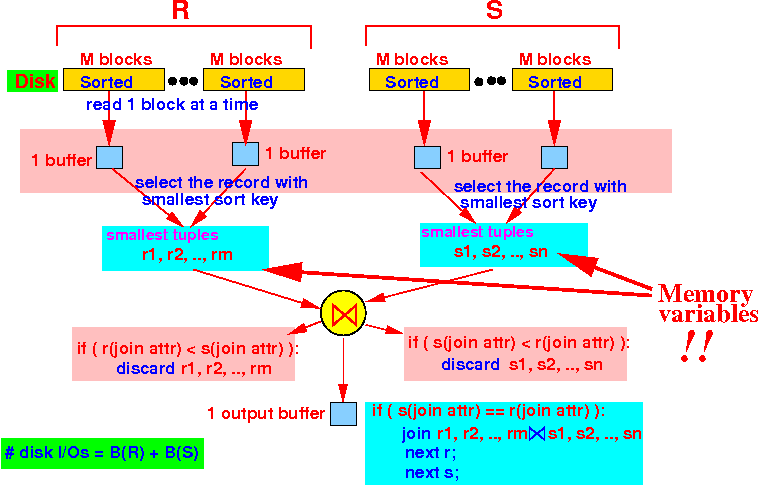
Pass 2: read 1 block from every (sorted) chunk and find the smallest tuple in each relation:
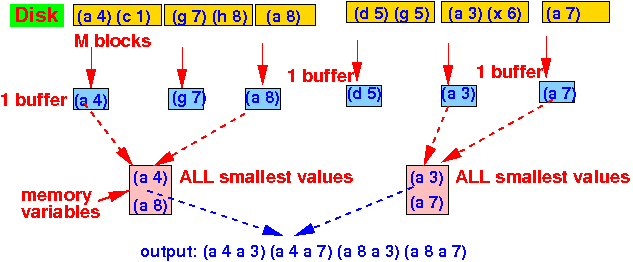
If R(smallest tuple value) =
S(smallest tuple value) then
join tuples and
advance R and S
If R(smallest tuple value) <
S(smallest tuple value) then
discard R's tuple
and
advance R
If R(smallest tuple value) >
S(smallest tuple value) then
output S's tuple and
advance S
Cost analysis of
the IO-efficient
2-pass TPMMS based join
(⋈) algorithm
Buffer requirement of
the IO-efficient
2-pass TPMMS based join
(⋈) algorithm
The relation R and S together must have at most M chunks, because Pass 2 can use at most M buffers:
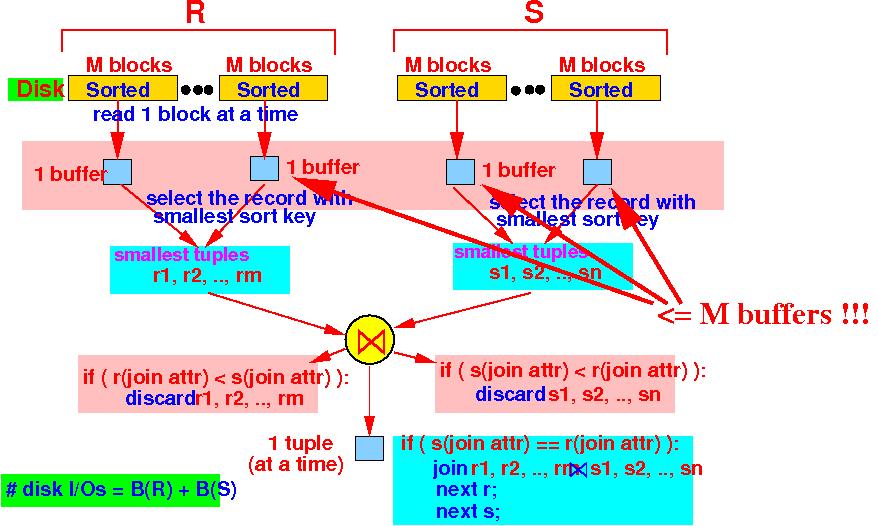
(We need to use 1 buffer to read 1 sorted chunk)
Buffer requirement of
the IO-efficient
2-pass TPMMS based join
(⋈) algorithm
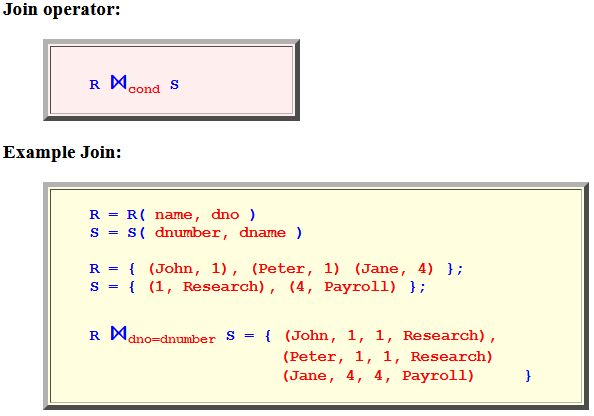
- Join operator:
R ⋈cond S - Example Join:
R = R( name, dno ) S = S( dnumber, dname ) R = { (John, 1), (Peter, 1) (Jane, 4) }; S = { (1, Research), (4, Payroll) }; R ⋈dno=dnumber S = { (John, 1, 1, Research), (Peter, 1, 1, Research) (Jane, 4, 4, Payroll) }
- Pre-requisite:
- If very few tuples with common join attributes values can be expected, we can use the following IO-efficient join algorithm that is based on TPMMS
- Phase 1:
(same as
TPMMS ---
you must do phase 1 on
both relations)
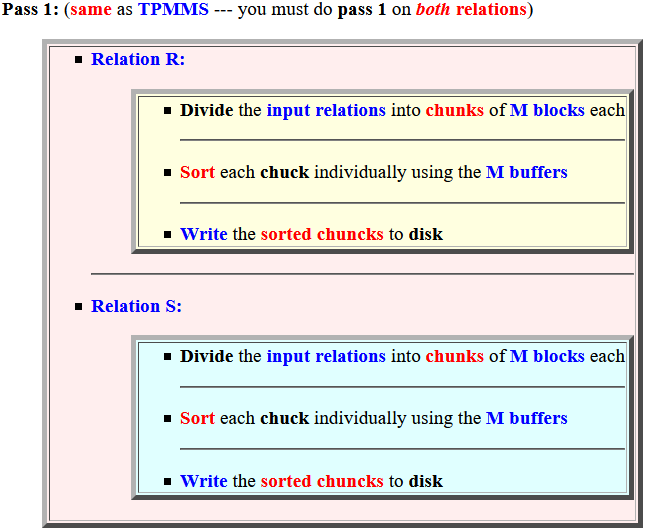
- Relation R:
- Divide the
input relations into
chunks of
M blocks each
- Sort each chuck
individually using the
M buffers
- Write the sorted chuncks to disk
- Divide the
input relations into
chunks of
M blocks each
- Relation S:
- Divide the
input relations into
chunks of
M blocks each
- Sort each chuck
individually using the
M buffers
- Write the sorted chuncks to disk
- Divide the
input relations into
chunks of
M blocks each
Graphically:
- Relation R:
- Phase 2:
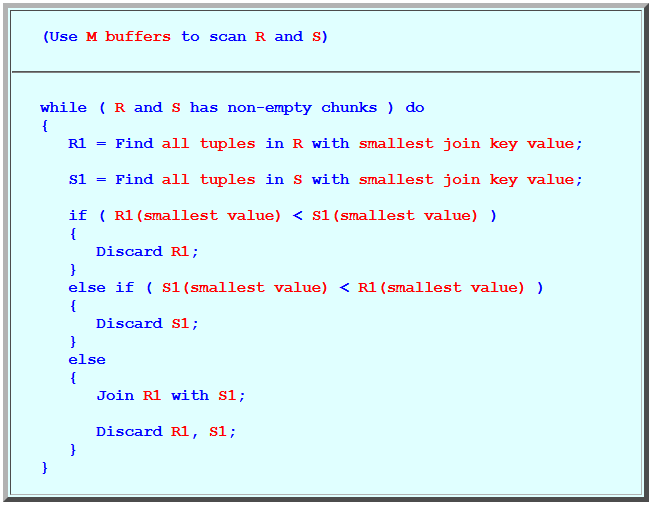
(Use M buffers to scan R and S)
while ( R and S has non-empty chunks ) do { R1 = Find all tuples in R with smallest join key value; S1 = Find all tuples in S with smallest join key value; if ( R1(smallest value) < S1(smallest value) ) { Discard R1; } else if ( S1(smallest value) < R1(smallest value) ) { Discard S1; } else { Join R1 with S1; Discard R1, S1; } }Graphically:
- Example:
- Inputs:

- Pass 1: sort
chunks of size
M blocks
- Pass 2: output
tuples with common join values
- Inputs:
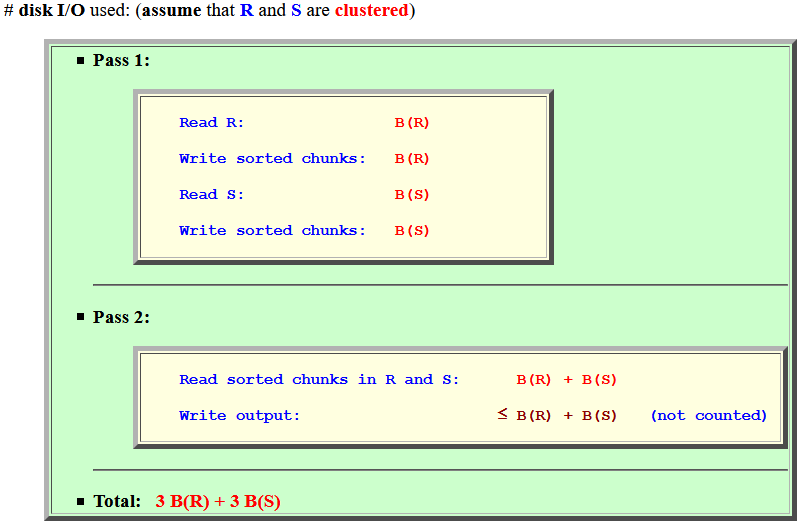
- # disk I/O used: (assume that
R is
clustered)
- Phase 1:
Read R: B(R) Write sorted chunks: B(R) Read S: B(S) Write sorted chunks: B(S)
- Phase 2:
Read sorted chunks in R and S: B(R) + B(S) Write output: ≤ B(R) + B(S) (not counted)
- Total: 3 B(R) + 3 B(S)
- Phase 1:
- Memory requirement:
- We can have at most
M chunks
in Phase 2:
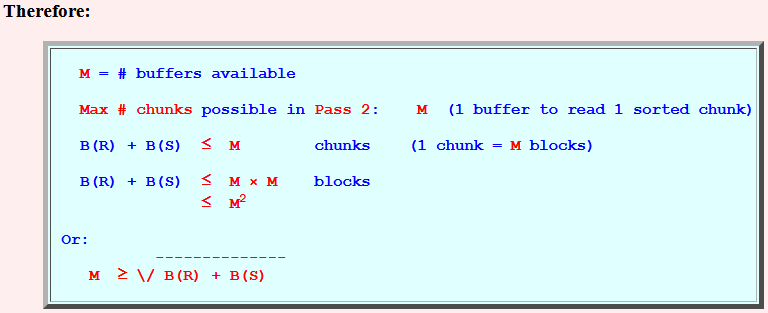
Therefore: total number of chunks of R and S --- together --- must be ≤ M
- Therefore:
B(R) + B(S) ≤ M chunks (1 chunk = M blocks) B(R) + B(S) ≤ M × M blocks ≤ M2 Or: -------------- M ≥ \/ B(R) + B(S)
But also:
- We need
some memory variables to
hold
joining tuples:
which we have assumed to be negligable (i.e.: small number of joining tuples)
- We can have at most
M chunks
in Phase 2: