- Dictatical note:
- I will present the
consistent hashing algorithm
in a piece meal fashion
- I start with a simplified version
that has:
- N storage nodes and N ranges
- Then present
a modified version that
has:
- N storage nodes and M ranges (N < M)
- Finally:
- add data replication to the method
- I will present the
consistent hashing algorithm
in a piece meal fashion
- A simplified version of
consistent hashing operates
as follows:
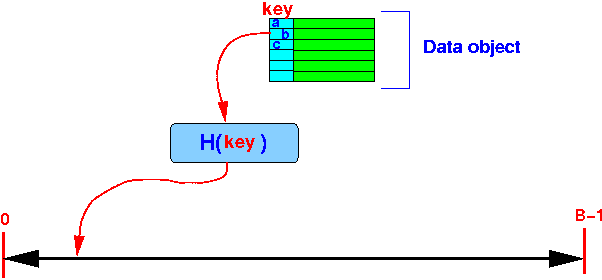
- Suppose
a hash function H(•)
hashes keys to
a range
[1 .. (B−1)]:
- Suppose
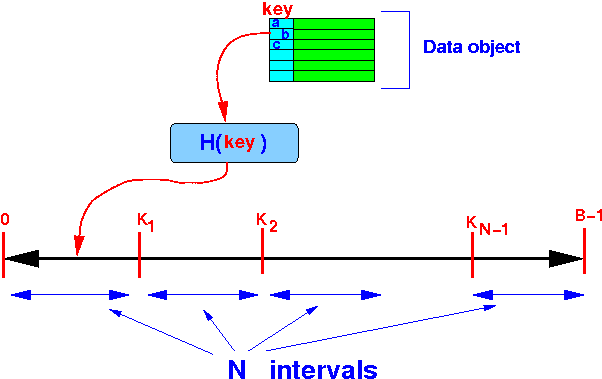
there are N data storage nodes:

- We divide the
range [0 .. (B−1)] into
N intervals:
- And assign
each interval to
a storage node:
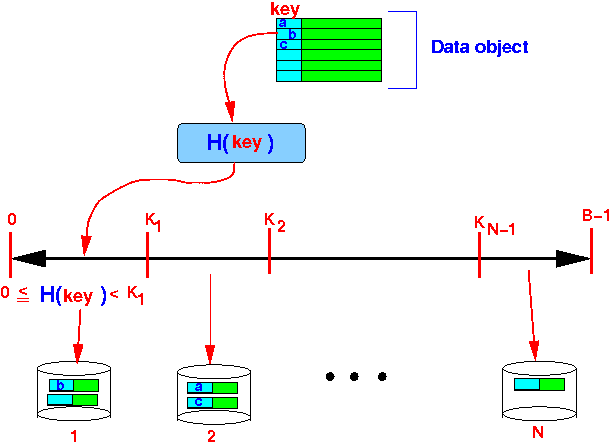
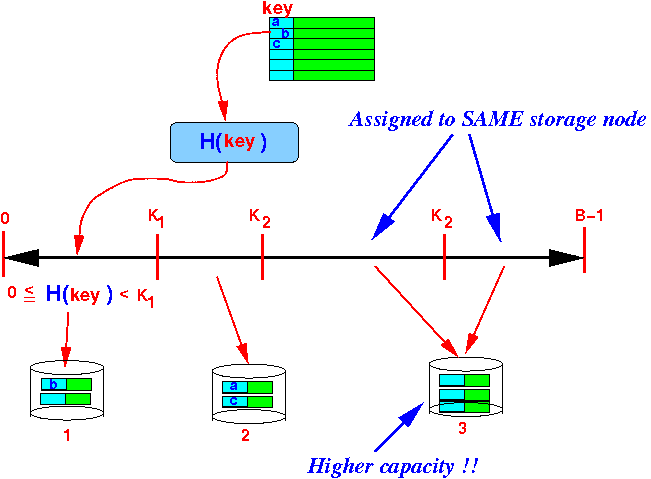
Example: (see above figure)
- The key b that hashes into a value in the first interval is stored on node 1
- Suppose
a hash function H(•)
hashes keys to
a range
[1 .. (B−1)]:
- A concrete example:
N = 3
- 3 ranges:
- [0 .. K1]
- [K1 .. K2]
- [K1 .. (B−1)]
- 3 storage nodes:
- 1, 2 and 3
- Mapping:
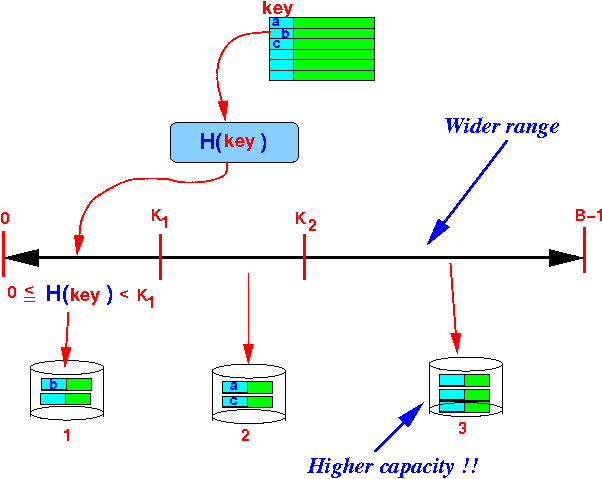
Notice that:
- The ranges can have
different width !!!
Example:
- Node 3 has
a highest capacity of
all nodes
- We give node 3 a wider range so it will store more data !!!
- Node 3 has
a highest capacity of
all nodes
- The ranges can have
different width !!!
- 3 ranges:
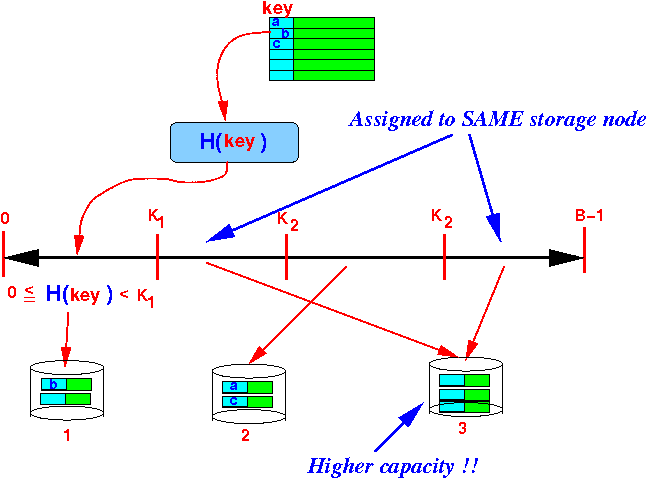
- Consider the following
example:
- 4 ranges:
- [0 .. K1]
- [K1 .. K2]
- [K2 .. K3]
- [K3 .. (B−1)]
- 3 storage nodes:
- 1, 2 and 3
- Mapping:
Notice that:
- Multiple ranges are
assigned to the
higher capacity node 3
(Range width can still be different !!!)
- Multiple ranges are
assigned to the
higher capacity node 3
- An alternative
assignment:
- 4 ranges: