- The hybrid algorithms
are adapted a little bit
(using multiple buckets)
to produce the
final algorithms
- The final algorithms
have a common prelude
and common postlude
- Common parts of the final algorithms:
/* --------------------------------------- Prelude (Sampling Scan) --------------------------------------- */ F = Scaled-Sample(R) with probability p; // Potentially heavy elements +------------------------------------------------+ | Actual scan... | | Do not include elements in F in the processing | | | | Assume the output is G | +------------------------------------------------+ /* --------------------------------------- Postlude (Cleaning Scan) --------------------------------------- */ F = G ∪ F; // Add F to G --> Potentially solutions F = Count(F); // Remove false positives
- The UNISCAN
method is the
Defer-Count algorithm
using
muiltple hashing functions
(and therefore,
multiple hasing buckets
- UNISCAN: using 2 hash functions
A1[1..(m/2)] = buckets used for hash function h1 A2[1..(m/2)] = buckets used for hash function h2
/* ---------------------- Prelude ---------------------- */ S = Scaled-Sample(R) using a suitable probab p; F = select f most frequent items in S;
*** Results: 1. Items in F are most likely heavy, but not guaranteed 2. F can contain false positives 3. F can contain false negatives
/* -------------------------------------------------------- Defer-Count: hash count without counting elements in F -------------------------------------------------------- */ /* ----------------------------- initialize counters ----------------------------- */ for ( i = 1; i <= m/2; i++ ) { A1[i] = 0; A2[i] = 0; } /* ------------------------------------ Hash-count items in R but not counting elements in F ------------------------------------ */ for ( each e ∈ R ∧ e ∉ F ) { A1[ h1( e ) ] ++; A2[ h2( e ) ] ++; }
*** Note: we have NOT potentially heavy elements Light elements that WERE hashed together with these elements will now be removed from F
/* ------------------------------ Form final solution set F ------------------------------ */ for ( each e ∈ R ) { /* ---------------------------------------------------- *** Add e only if both counts exceed threshold ---------------------------------------------------- */ if ( A1[ h1( e ) ] ≥ T AND A2[ h2( e ) ] ≥ T ) add e to F; } // At this point, F may have false positives. // But: F will not miss any heavy elements !
Properties of F: F has false positive F has no false negatives - every heavy element will be included in F !
/* ---------------------- Postlude ---------------------- */ F = Count(F); // Remove false positives ! // F will not have any false positives !!
- In MULTISCAN,
we perform
multiple passes
of the Defer-Count
procedure.
The result of each pass is summarised in a bit array variable.
- MULTISCAN: (using 2 passes)
/* -------------------------------- Prelude -------------------------------- */ S = Scaled-Sample(R) using a suitable probab p; F = select f most frequent items in S;
*** Results: 1. Items in F are most likely heavy, but not guaranteed 2. F can contain false positives 3. F can contain false negatives
/* -------------------------------------------------------- Defer-Count pass 1 -------------------------------------------------------- */ /* ----------------------------- initialize counters ----------------------------- */ for ( i = 1; i <= m; i++ ) A[i] = 0; /* ------------------------------------ Hash-count items in R but not counting elements in F ------------------------------------ */ for ( each e ∈ R ∧ e ∉ F ) A[ h1( e ) ] ++; // Note: 2 items e1 and e2 that hashes // to the same value will be counted together... /* ------------------------------ Store away the summary ------------------------------ */ for ( i = 1; i <= m; i ++ ) BITMAP1[i] = 0; for ( each v ∈ R ) { if ( A[ h1( e ) ] ≥ T ) BITMAP1[h1( e )] = 1; }
/* -------------------------------------------------------- Defer-Count pass 2 -------------------------------------------------------- */ /* ----------------------------- initialize counters ----------------------------- */ for ( i = 1; i <= m; i++ ) A[i] = 0; /* ------------------------------------ Hash-count items in R but not counting elements in F ------------------------------------ */ for ( each e ∈ R ∧ e ∉ F ) A[ h2( e ) ] ++; // Note: 2 items e1 and e2 that hashes // to the same value will be counted together... /* ------------------------------ Store away the summary ------------------------------ */ for ( i = 1; i <= m; i ++ ) BITMAP2[i] = 0; for ( each v ∈ R ) { if ( A[ h1( e ) ] ≥ T ) BITMAP2[h1( e )] = 1; }
/* ------------------------------ Form final solution set F ------------------------------ */ for ( each v ∈ R ) { if ( BITMAP1[ h1( e ) ] == 1 AND BITMAP2[ h2( e ) ] == 1 ) add e to F; } // At this point, F may have false positives. // But: F will not miss any heavy elements !
Properties of F: F has false positive F has no false negatives - every heavy element will be included in F !
/* -------------------- Postlude -------------------- */ F = Count(F); // Remove false positives ! // F will not have any false positives !!
- NOTE:
- The MULTISACN algorithm
can store the
BITMAP[]
variables
on disk
to save
main memory
- The authors
presented a modified version
of the
MULTISCAN algorithm
that performs the
bitwise AND operation
during the scans.
I will not present this version because it does not add new stuff much to the discussion...
- The MULTISACN algorithm
can store the
BITMAP[]
variables
on disk
to save
main memory
- Effect of the amount of memory on the candidate set F:
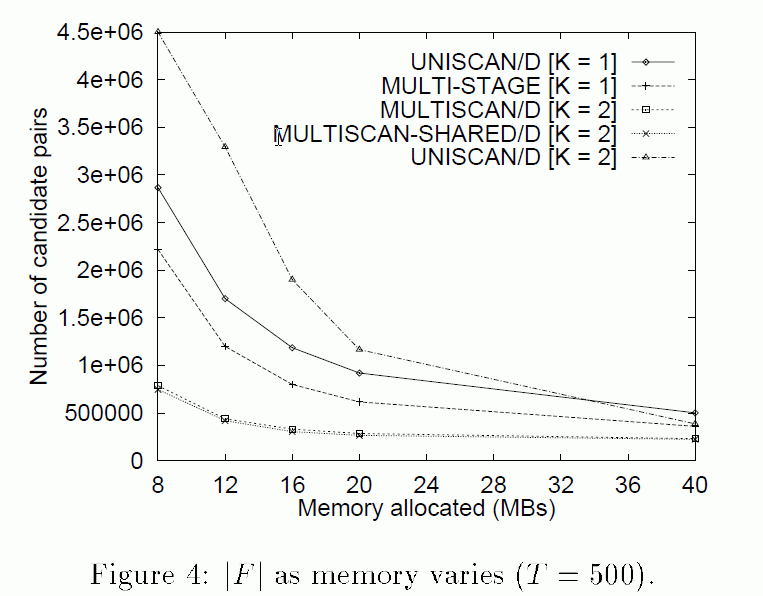
Conclusion:
- The more memory, the smaller (better) the candidate set F
- Effect of the amount of memory on the running time:
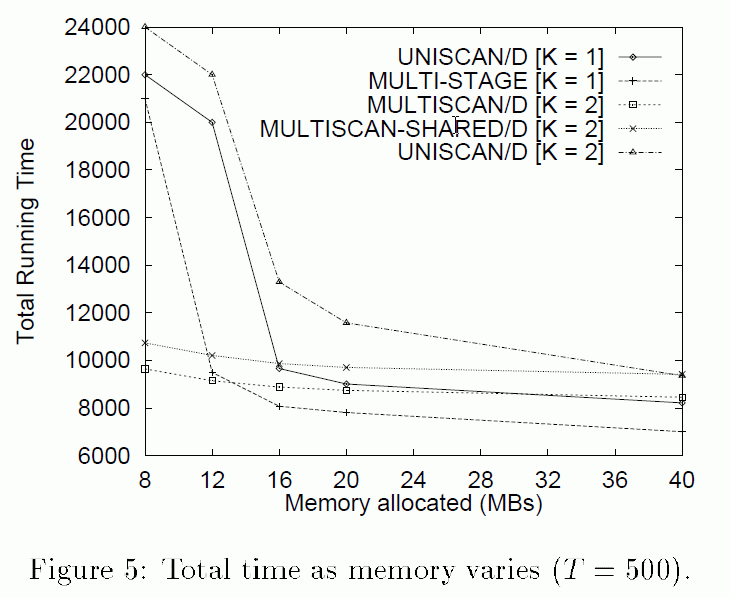
Conclusion:
- The more memory, the
smaller (better)
the running time
That is because the candidate set F is smaller, so the processing of the false positives is faster
- The more memory, the
smaller (better)
the running time