Tasks where threads must
coorporate
Dependency of thread executions
|
Tasks where threads
must coorporate
Consider a task performed by 2 (parallel) threads where thread 1 must use the new value of y:
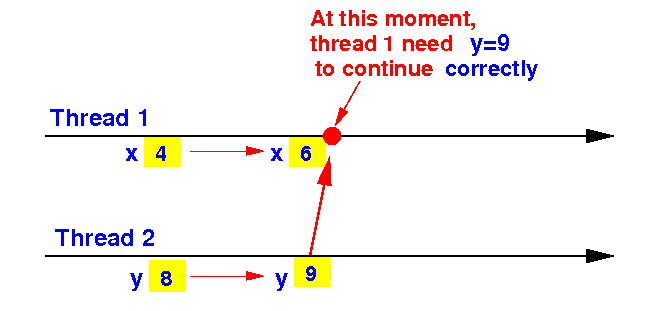
Correctness condition:
|
Tasks where threads
must coorporate
Suppose thread 1's progress was faster:
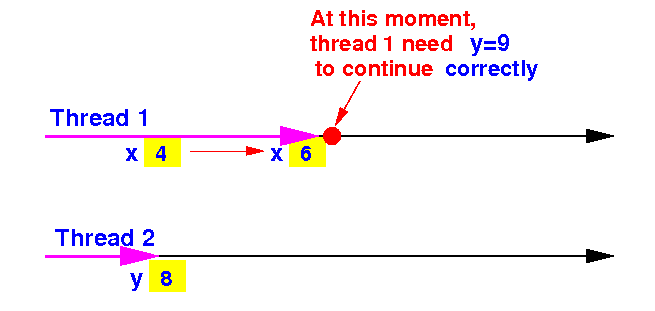
What will
happen if:
|
Tasks where threads
must coorporate
IF thread 1 continues execution, it will use the old value y=8:
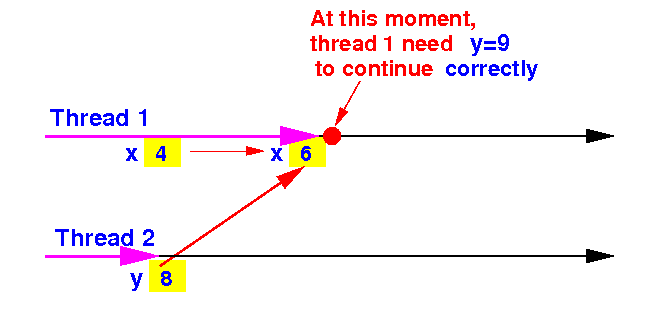
The
correctness condition is
violated and
we will have:
|
Tasks where threads
must coorporate
Sometimes, the thread executions must "meet up" The "meet up" point is called a synchronization point:
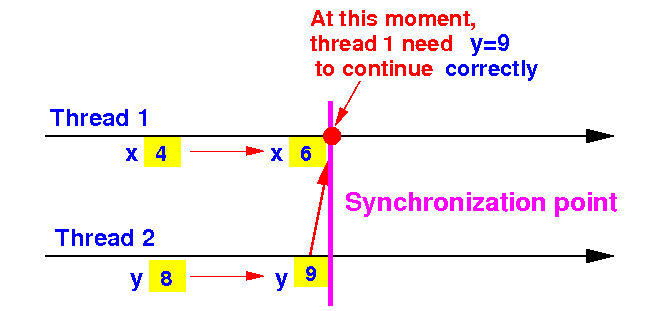
This problem known in Computer Science as a synchronization problem
Array reduction:
a task where
threads must
synchronize
The array reduction problem:
|
Array reduction:
a task where
threads must
synchronize
An example of the array reduction problem:
|
A CPU algorithm
for the array reduction problem
The CPU algorithm for the array reduction problem is as follows:
void reduce(int a[], int n)
{
int i;
for (i = 1; i < n; i++)
a[i] = a[i] + a[i-1];
}
|
Example:
A[0] = 1 i=1 A[1] = 2 A[2] = 3 A[3] = 4 |
A CPU algorithm
for the array reduction problem
The CPU algorithm for the array reduction problem is as follows:
void reduce(int a[], int n)
{
int i;
for (i = 1; i < n; i++)
a[i] = a[i] + a[i-1];
}
|
Example:
A[0] = 1 i=1 A[1] = 2+1=3 A[2] = 3 A[3] = 4 |
A CPU algorithm
for the array reduction problem
The CPU algorithm for the array reduction problem is as follows:
void reduce(int a[], int n)
{
int i;
for (i = 1; i < n; i++)
a[i] = a[i] + a[i-1];
}
|
Example:
A[0] = 1 i=2 A[1] = 2+1=3 A[2] = 3+3=6 A[3] = 4 |
A CPU algorithm
for the array reduction problem
The CPU algorithm for the array reduction problem is as follows:
void reduce(int a[], int n)
{
int i;
for (i = 1; i < n; i++)
a[i] = a[i] + a[i-1];
}
|
Example:
A[0] = 1 i=3
A[1] = 2+1=3
A[2] = 3+3=6
A[3] = 4+6=10 (Running time = O(N))
|
A parallel algorithm for
array reduction
I will use an array of 8 elements as example to illustrate the parallel algorithm 20

A parallel algorithm for
array reduction
We create 8 threads and assign thread i to compute the final value of a[i]: 20
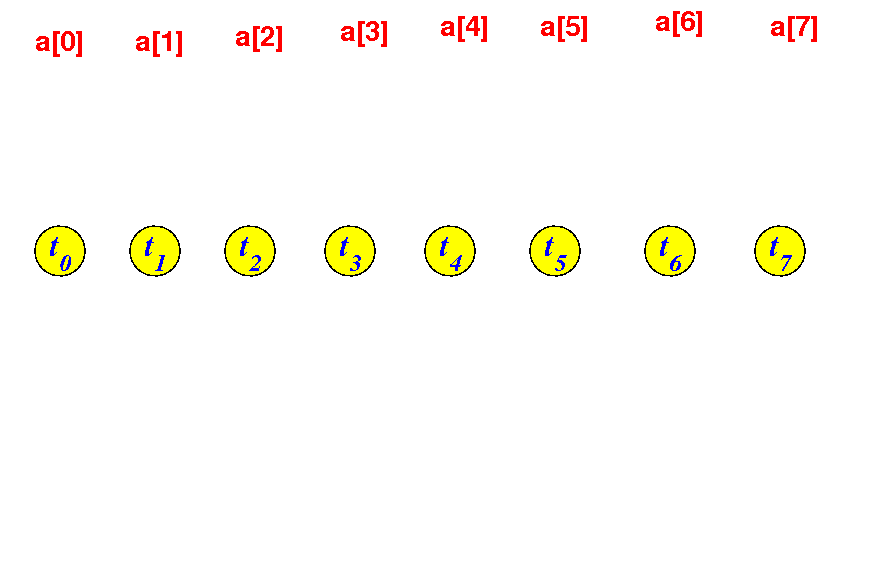
The algorithm will execute in log2(N) rounds...
A parallel algorithm for
array reduction
In round 1, threads with thrID ≥ 1 (21-1) performs: a[thrID] = a[thrID] + a[thrID-1]:
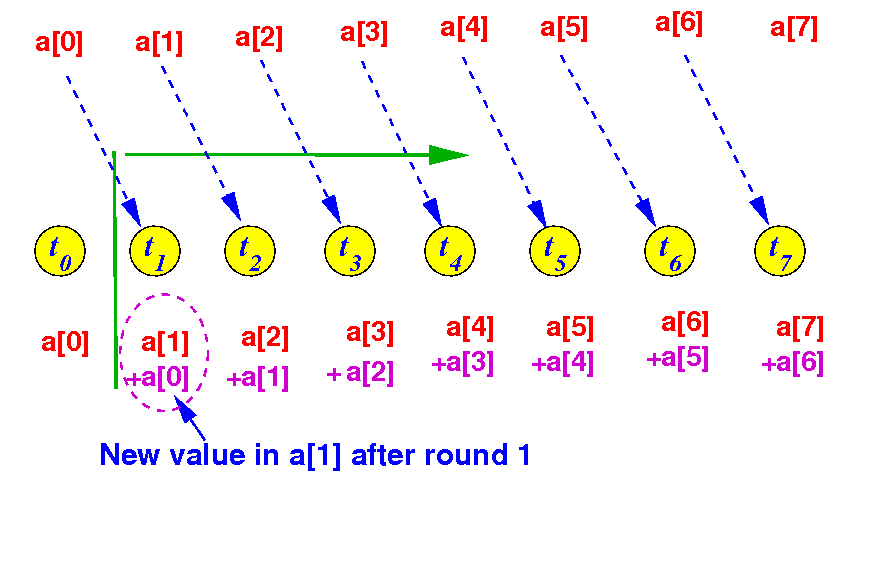
A parallel algorithm for
array reduction
When round 1 completes, the values in the array elements are: 20
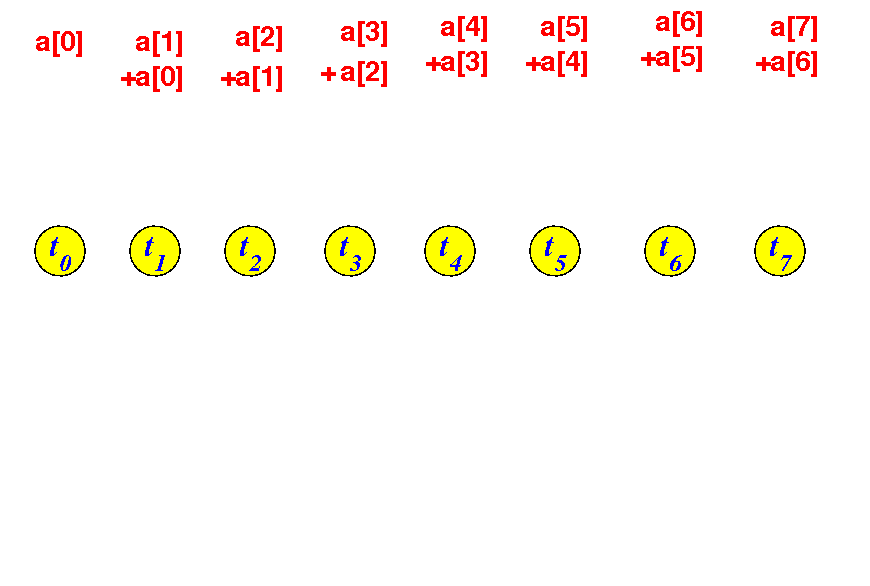
Then round 2 will start...
A parallel algorithm for
array reduction
In round 2, threads with thrID ≥ 2 (22-1) performs: a[thrID] = a[thrID] + a[thrID-2]:
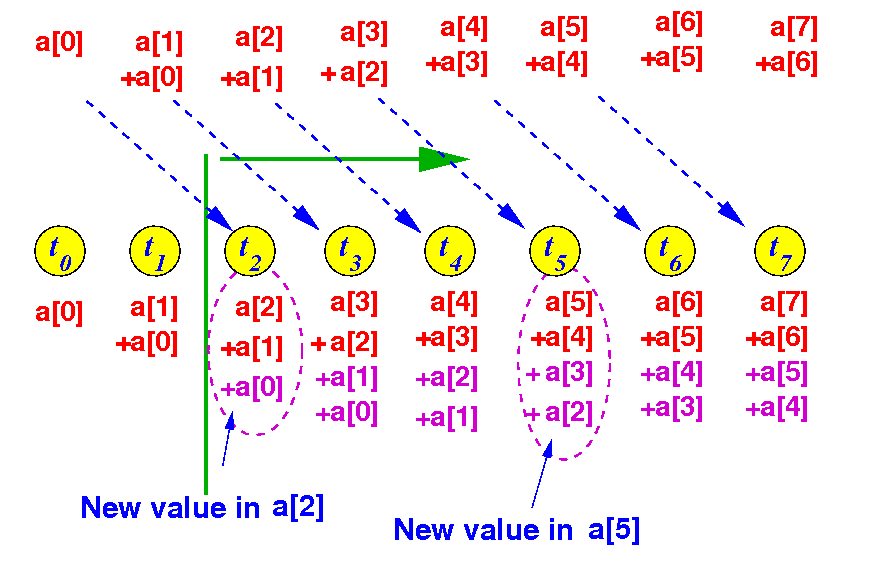
A parallel algorithm for
array reduction
When round 2 completes, the values in the array elements are: 20

Then round 3 will start...
A parallel algorithm for
array reduction
In round 3, threads with thrID ≥ 4 (23-1) performs: a[thrID] = a[thrID] + a[thrID-4]:
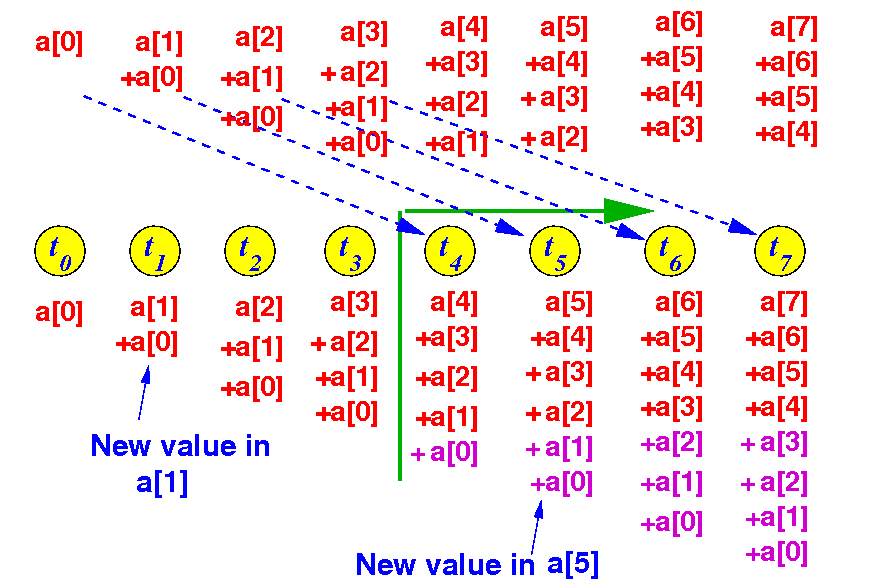
We are done in 3 (= log2(8)) steps !!!
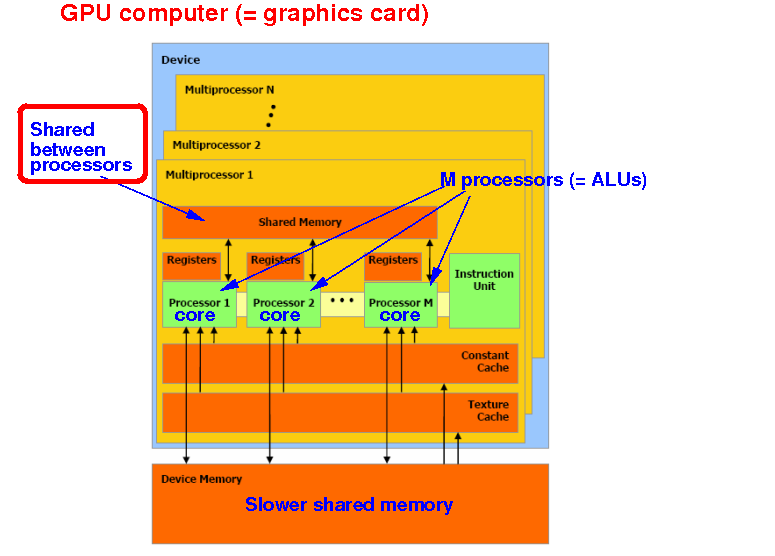
Background Information: thread communication
|
The CUDA
array reudction algorithm -
the CPU part
The CPU code (1) allocate arrays and (2) then launches the 512 threads (as <<< B,T >>>):
// We reduce an array of 512 element int main (int argc, char *argv[]) { int *arr; int N; int i; N = 512; // Fixed length for simplicity cudaMallocManaged( &arr, N*sizeof(int) ); for ( i = 0 ; i < N; i++ ) arr[i] = 1; // A[i] = 1 reduce<<< 1 ,N >>>(arr, N); // Note: must use 1 block to communicate cudaDeviceSynchronize(); |
The result of the array reduction operation will be: A[0]=1, A[1]=2, ..., A[511]=512
The CUDA
array reudction algorithm -
the GPU part
For N=512, there are 9 rounds of executions:
__global__ void reduce(int *a, int n)
{
int myID = blockDim.x*blockIdx.x + threadIdx.x;
if ( myID >= 1 && myID < n) // Round 1
a[myID] += a[myID-1];
if ( myID >= 2 && myID < n) // Round 2
a[myID] += a[myID-2];
if ( myID >= 4 && myID < n) // Round 3
a[myID] += a[myID-4];
if ( myID >= 8 && myID < n) // Round 4
a[myID] += a[myID-8];
if ( myID >= 16 && myID < n) // Round 5
a[myID] += a[myID-16];
if ( myID >= 32 && myID < n) // Round 6
a[myID] += a[myID-32];
if ( myID >= 64 && myID < n) // Round 7
a[myID] += a[myID-64];
if ( myID >= 128 && myID < n) // Round 8
a[myID] += a[myID-128];
if ( myID >= 256 && myID < n) // Round 9
a[myID] += a[myID-256];
}
|
DEMO: /home/cs355001/demo/CUDA/6-reduction/array-reduce1.cu
Results from running the CUDA
array reduction program
Here is a result from the CUDA array reduction program:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 114 115 117 118 120 121 123 124 126 127 129 130 132 133 135 136 138 139 141 142 144 145 147 148 150 151 153 154 156 157 159 160 146 147 149 150 152 153 155 156 158 159 161 162 164 165 167 168 170 171 173 174 176 177 179 180 182 183 185 186 188 189 191 192 178 179 181 182 184 185 187 188 190 191 193 194 196 197 199 200 202 203 205 206 208 209 211 212 214 215 217 218 220 221 223 224 210 211 213 214 216 217 219 220 222 223 225 226 228 229 231 232 234 235 237 238 240 241 243 244 246 247 249 250 252 253 255 256 242 243 245 246 248 249 251 252 254 255 257 258 260 261 263 264 266 267 269 270 272 273 275 276 278 279 281 282 284 285 287 288 274 275 277 278 280 281 283 284 286 287 289 290 292 293 295 296 298 299 301 302 304 305 307 308 310 311 313 314 316 317 319 320 291 292 295 296 299 300 303 304 307 308 311 312 315 316 319 320 323 324 327 328 331 332 335 336 339 340 343 344 347 348 351 352 323 324 327 328 331 332 335 336 339 340 343 344 347 348 351 352 355 356 359 360 363 364 367 368 371 372 375 376 379 380 383 384 355 356 359 360 363 364 367 368 371 372 375 376 379 380 383 384 387 388 391 392 395 396 399 400 403 404 407 408 411 412 415 416 373 374 377 378 383 384 387 388 393 394 397 398 403 404 407 408 413 414 417 418 423 424 427 428 433 434 437 438 443 444 447 448 405 406 409 410 415 416 419 420 425 426 429 430 435 436 439 440 445 446 449 450 455 456 459 460 465 466 469 470 475 476 479 480 425 426 429 430 435 436 439 440 449 450 453 454 459 460 463 464 473 474 477 478 483 484 487 488 497 498 501 502 507 508 511 512 |
Looks like it correct....
Results from running the CUDA
array reduction program
But sometimes you will get:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 96 66 67 69 70 72 73 75 76 78 79 81 82 84 85 87 88 90 91 93 94 96 97 99 100 102 103 105 106 108 109 111 112 114 115 117 118 120 121 123 124 126 127 129 130 132 133 135 136 138 139 141 142 144 145 147 148 150 151 153 154 156 157 159 160 145 145 146 146 147 147 148 148 149 149 150 150 151 151 152 152 153 153 154 154 155 155 156 156 157 157 158 158 159 159 160 160 149 149 150 150 151 151 152 152 157 157 158 158 159 159 160 160 165 165 166 166 167 167 168 168 173 173 174 174 175 175 176 176 182 183 185 186 188 189 191 192 198 199 201 202 204 205 207 208 214 215 217 218 220 221 223 224 230 231 233 234 236 237 239 240 214 215 217 218 220 221 223 224 230 231 233 234 236 237 239 240 246 247 249 250 252 253 255 256 262 263 265 266 268 269 271 272 178 179 181 182 184 185 187 188 190 191 193 194 196 197 199 200 202 203 205 206 208 209 211 212 214 215 217 218 220 221 223 224 262 262 264 264 266 266 268 268 274 274 276 276 278 278 280 280 286 286 288 288 290 290 292 292 298 298 300 300 302 302 304 304 279 280 283 284 287 288 291 292 299 300 303 304 307 308 311 312 319 320 323 324 327 328 331 332 339 340 343 344 347 348 351 352 323 324 327 328 331 332 335 336 347 348 351 352 355 356 359 360 363 364 367 368 371 372 375 376 387 388 391 392 395 396 399 400 302 302 304 304 306 306 308 308 314 314 316 316 318 318 320 320 318 318 320 320 322 322 324 324 330 330 332 332 334 334 336 336 260 260 262 262 266 266 268 268 280 280 282 282 286 286 288 288 292 292 294 294 298 298 300 300 312 312 314 314 318 318 320 320 |
Something went wrong !!
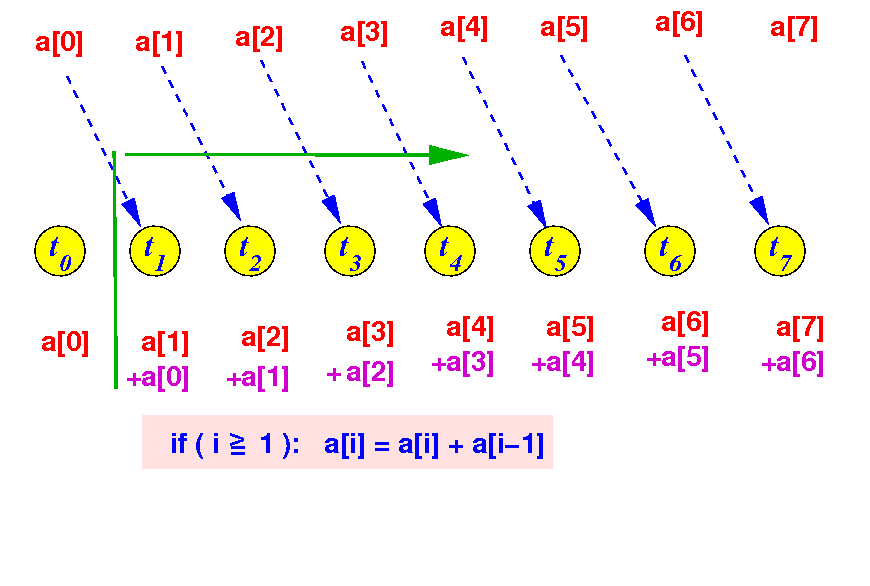
The synchronization problem in
array reduction
Consider round 1 of the array reduction algorithm:
The synchronization problem in
array reduction
Suppose thread 3 was slower and finishes later:
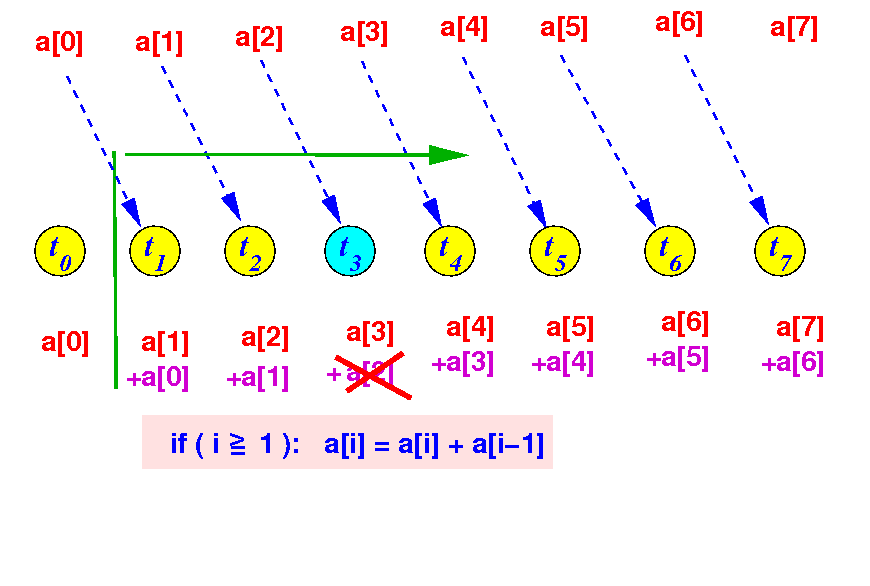
The synchronization problem in
array reduction
This delay will cause a[5] to be computed incorrectly in round 2:
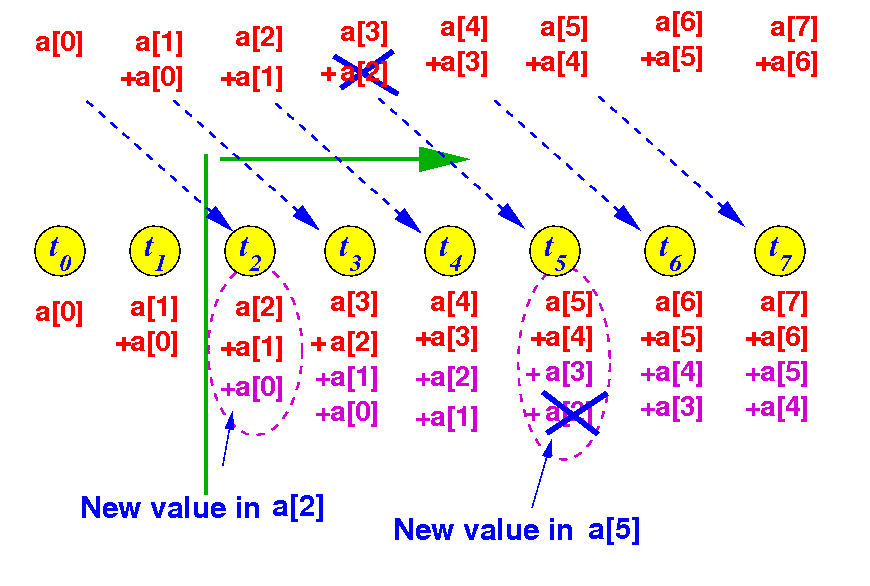
Therefore: round 1 must finish completely before round 2 can begin !!!
The CUDA library
__synchronize( )
function
|
We can use the __syncthreads( ) to fix the synchronization problem in the array reduction algorithm
The CUDA
array reudction algorithm -
the GPU part
The unsynchronized GPU kernel function for array reduction:
__global__ void reduce(int *a, int n)
{
int myID = blockDim.x*blockIdx.x + threadIdx.x;
if ( myID >= 1 && myID < n) // Round 1
a[myID] += a[myID-1];
if ( myID >= 2 && myID < n) // Round 2
a[myID] += a[myID-2];
if ( myID >= 4 && myID < n) // Round 3
a[myID] += a[myID-4];
if ( myID >= 8 && myID < n) // Round 4
a[myID] += a[myID-8];
if ( myID >= 16 && myID < n) // Round 5
a[myID] += a[myID-16];
if ( myID >= 32 && myID < n) // Round 6
a[myID] += a[myID-32];
if ( myID >= 64 && myID < n) // Round 7
a[myID] += a[myID-64];
if ( myID >= 128 && myID < n) // Round 8
a[myID] += a[myID-128];
if ( myID >= 256 && myID < n) // Round 9
a[myID] += a[myID-256];
}
|
The CUDA
array reudction algorithm -
the GPU part
We synchronize all threads at the end of each round:
__global__ void reduce(int *a, int n)
{
int myID = blockDim.x*blockIdx.x + threadIdx.x;
if ( myID >= 1 && myID < n) // Round 1
a[myID] += a[myID-1];
__synthreads( );
if ( myID >= 2 && myID < n) // Round 2
a[myID] += a[myID-2];
__synthreads( );
if ( myID >= 4 && myID < n) // Round 3
a[myID] += a[myID-4];
__synthreads( );
if ( myID >= 8 && myID < n) // Round 4
a[myID] += a[myID-8];
__synthreads( );
if ( myID >= 16 && myID < n) // Round 5
a[myID] += a[myID-16];
__synthreads( );
if ( myID >= 32 && myID < n) // Round 6
a[myID] += a[myID-32];
__synthreads( );
if ( myID >= 64 && myID < n) // Round 7
a[myID] += a[myID-64];
__synthreads( );
if ( myID >= 128 && myID < n) // Round 8
a[myID] += a[myID-128];
__synthreads( );
if ( myID >= 256 && myID < n) // Round 9
a[myID] += a[myID-256];
__synthreads( );
}
|
DEMO: /home/cs355001/demo/CUDA/6-reduction/array-reduce2.cu
Using ≥ 2 blocks
in array reduction
|
DEMO: demo/CUDA/6-reduction/array-reduce3.cu --- use N=2049