The vector addition algorithm for the
CPU
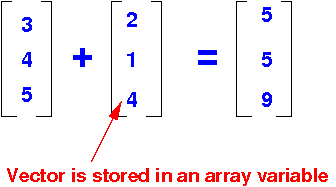
Vector addition is adding corresponding array elements in a "vector" (stored as an array):
I will first show you an algorithm for a CPU
Then I will show you an algorithm for a GPU
A CPU algorithm for
vector addition
int main(int argc, char *argv[])
{
int i, N; // N = vector length
float *x, *y, *z; // Base addresses of arrays
/* ==========================================
Allocate arrays to store vector x and y
========================================== */
x = malloc( N*sizeof(float) ); // Allocate array of N floats
y = malloc( N*sizeof(float) ); // Allocate array of N floats
z = malloc( N*sizeof(float) ); // Allocate array of N floats
/* Initialize array x and y omitted */
for (i = 0; i < N; i++)
z[i] = x[i] + y[i]; // CPU's array addition
}
|
DEMO: /home/cs355001/demo/CUDA/3-add-vector/cpu-add-vector.c
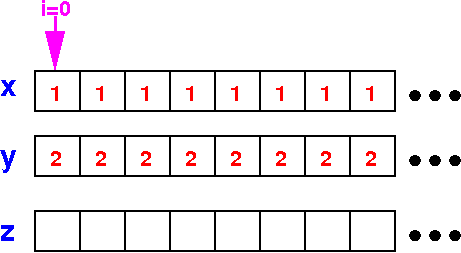
Execution of the
CPU algorithm
of vector addition
Initial state:
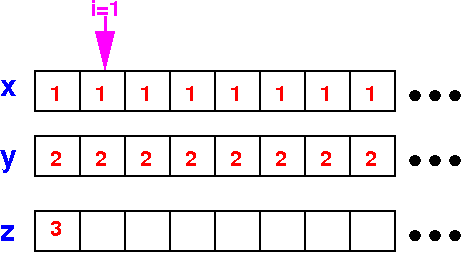
Execution of the
CPU algorithm
of vector addition
After 1 iteration:
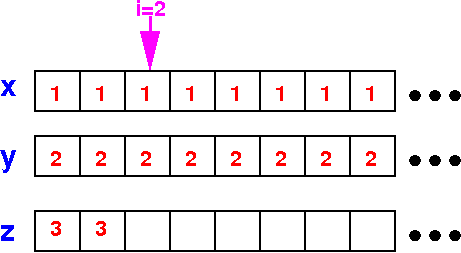
Execution of the
CPU algorithm
of vector addition
After 2 iterations:
And so on...
GPU's execution of
the vector addition algorithm
Recall that a grid has B blocks with T (T ≤ 1024) threads per block:
#include <stdio.h>
#include <unistd.h>
__global__ void hello( )
{
printf("gridDim.x=%d, blockIdx.x=#%d,
blockDim.x=%d, threadIdx.x=#%d -> ID=%d\n",
gridDim.x, blockIdx.x, blockDim.x, threadIdx.x,
blockIdx.x*blockDim.x+threadIdx.x);
}
int main()
{
hello<<< B, T >>>( );
printf("I am the CPU: Hello World ! \n");
cudaDeviceSynchronize();
}
|
Each thread can compute its unique ID using blockIdx.x*blockDim.x+threadIdx.x.
How to set the
parameters B (# thread blocks) and
T (# threads/block) ?
Suppose we must add 2 vectors (= arrays) of size N:
Suppose we add arrays of size N:
x[0] x[1] x[2] ... ... ... ... ... ... ... ... ... x[N-1]
+ + + + + + +
y[0] y[1] y[2] ... ... ... ... ... ... ... ... ... y[N-1]
|
How to set the
parameters B (# thread blocks) and
T (# threads/block) ?
We create N threads and use thread i to compute x[i] + y[i]:
Suppose we add arrays of size N:
x[0] x[1] x[2] ... ... x[i]... ... ... ... ... ... x[N-1]
+ + + + + + + +
y[0] y[1] y[2] ... ... y[i]... ... ... ... ... ... y[N-1]
^
|
thread i
<--------------------------------------------------------->
N threads
Problem: what if N > 1024 ??
|
Important restriction: 1 block can have at most 1024 threads
How to set the
parameters B (# thread blocks) and
T (# threads/block) ?
To create an N threads, we divide the N threads up into blocks of T threads with: T ≤ 1024:
Suppose we add arrays of size N:
x[0] x[1] x[2] ... ... x[i]... ... ... ... ... ... x[N-1]
+ + + + + + + +
y[0] y[1] y[2] ... ... y[i]... ... ... ... ... ... y[N-1]
<----------------> <--------------> ....... <-------------->
T threads T threads T threads (T < 1024)
(1 block) (1 block) ... (1 block)
<--------------------------------------------------------->
N threads
|
We can choose the value of T, as long as: T ≤ 1024 (T can affect performance !)
How to set the
parameters B (# thread blocks) and
T (# threads/block) ?
The # block in the grid is equal to ⌈N/T⌉
Suppose we add arrays of size N:
x[0] x[1] x[2] ... ... x[i]... ... ... ... ... ... x[N-1]
+ + + + + + + +
y[0] y[1] y[2] ... ... y[i]... ... ... ... ... ... y[N-1]
<----------------> <--------------> ....... <-------------->
T threads T threads T threads (T < 1024)
(1 block) (1 block) ... (1 block)
| |
+-------------------------------------------------------+
# blocks B = ⌈ N/T ⌉
|
How to set the
parameters B (# thread blocks) and
T (# threads/block) ?
Notice that we may create > N threads:
Suppose we add arrays of size N:
x[0] x[1] x[2] ... ... x[i]... ... ... ... ... ... x[N-1]
+ + + + + + + +
y[0] y[1] y[2] ... ... y[i]... ... ... ... ... ... y[N-1]
<----------------> <--------------> ....... <-------------->
T threads T threads T threads (T < 1024)
(1 block) (1 block) ... (1 block)
| |
+-------------------------------------------------------+
# blocks B = ⌈ N/T ⌉
Example:
N = 3500
T = 1000
--> B = ⌈ 3500/1000 ⌉ = 4 thread blocks
We will create 4 × 1000 = 4000 threads !!
|
Warning: threads with ID ≥ N must not execute the vector addition code !!!
The CUDA vector addition algorithm -
CPU part
The CPU code: (1) allocate arrays and (2) then launches the threads (as <<< B,T >>>):
int main(int argc, char *argv[])
{
int N = Vector size
}
|
N will be specified by the user input
The CUDA vector addition algorithm -
CPU part
The variable T is the number of threads in a block:
int main(int argc, char *argv[])
{
int N = Vector size
int T = # threads per thread block (user choice)
}
|
We can select a value for T (with the condition that T ≤ 1024)
The CUDA vector addition algorithm -
CPU part
The number of blocks in the grid is:
int main(int argc, char *argv[])
{
int N = Vector size
int T = # threads per thread block (user choice)
int B = ceil((float) N / T ); // # thread blocks needed
}
|
We will create the "unified" shared array variables next...
The CUDA vector addition algorithm -
CPU part
We define the reference variables to allocate the shared arrays:
int main(int argc, char *argv[])
{
int N = Vector size
int T = # threads per thread block (user choice)
int B = ceil((float) N / T ); // # thread blocks needed
float *a, *b, *c;
}
|
Next we allocate the arrays in the unified memory system
The CUDA vector addition algorithm -
CPU part
Allocate the 3 shared vectors (as 1-dim arrays):
int main(int argc, char *argv[])
{
int N = Vector size
int T = # threads per thread block (user choice)
int B = ceil((float) N / T ); // # thread blocks needed
float *a, *b, *c;
/* =======================================
Allocate 3 shared matrices (as arrays)
======================================= */
cudaMallocManaged(&a, N*sizeof(float));
cudaMallocManaged(&b, N*sizeof(float));
cudaMallocManaged(&c, N*sizeof(float));
// initialize x and y arrays (code omitted)
}
|
(This is CUDA syntax... i.e, how CUDA provide the dynamic shared array to us)
The CUDA vector addition algorithm -
CPU part
Launch (at least) N threads as <<< B,T >>> to perform the vector addition:
int main(int argc, char *argv[])
{
int N = Vector size
int T = # threads per thread block (user choice)
int B = ceil((float) N / T ); // # thread blocks needed
float *a, *b, *c;
/* =======================================
Allocate 3 shared matrices (as arrays)
======================================= */
cudaMallocManaged(&a, N*sizeof(float));
cudaMallocManaged(&b, N*sizeof(float));
cudaMallocManaged(&c, N*sizeof(float));
// initialize x and y arrays (code omitted)
vectorAdd<<< B, T >>>(a, b, c, N); // Launch kernel
cudaDeviceSynchronize();
// Print result in c
}
|
Next: we will write the kernel code for vectorAdd( )....
The CUDA vector addition algorithm -
GPU part
Let each thread computes its own unique ID i:
__global__ void add(float *x, float *y, float *z, int n)
{
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
}
|
The CUDA vector addition algorithm -
GPU part
The thread i on the GPU must compute z[i] = x[i] + y[i]:
__global__ void add(float *x, float *y, float *z, int n)
{
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
z[i] = x[i] + y[i];
}
|
But: only for the threads where i < N:
The CUDA vector addition algorithm -
GPU part
We can prevent threads with i ≥ N from executing some instructions as follows:
__global__ void add(float *x, float *y, float *z, int n)
{
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
if ( i < n )
{
z[i] = x[i] + y[i];
}
}
|
DEMO: /home/cs355001/demo/CUDA/3-add-vector/gpu-add-vector.cu