CUDA program:
kernel
Kernel = the program (function) that is executed by the GPU
Example:
__global__ void hello( )
{
printf("Hello World\n");
// CUDA C code
// uses printf( ) in CUDA C library
}
|
A kernel (= a GPU function/program) is executed by a grid (of threads)
Note:
|
Threads
(terminology)
Thread = single execution unit that run CUDA code ("kernel") on the GPU
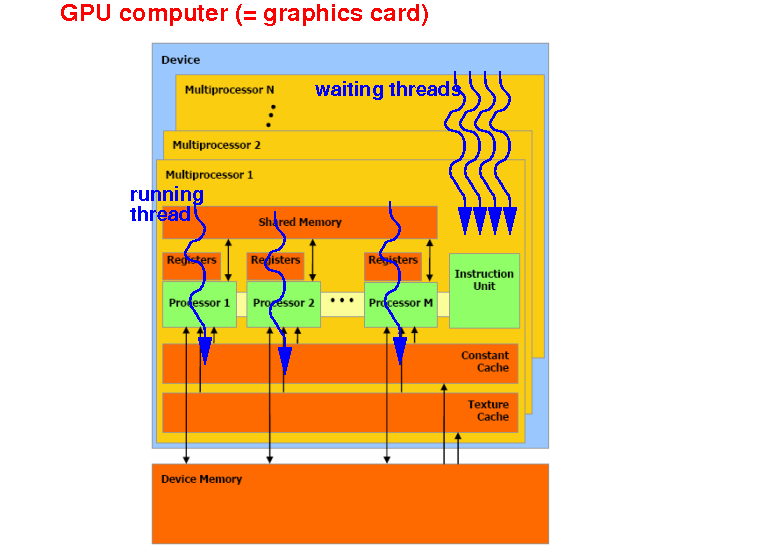
Each thread is
executed by
1 CUDA core (= processor)
Multiple threads can be
assigned to the
same
CUDA core
(A CUDA core will
switch execution
between different threads !)
Thread organization:
thread block
|
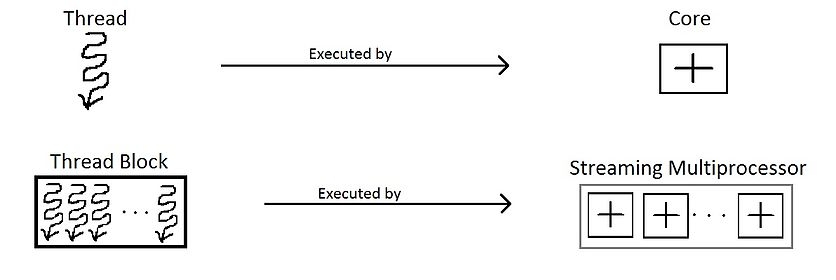
Thread organization:
grid
|
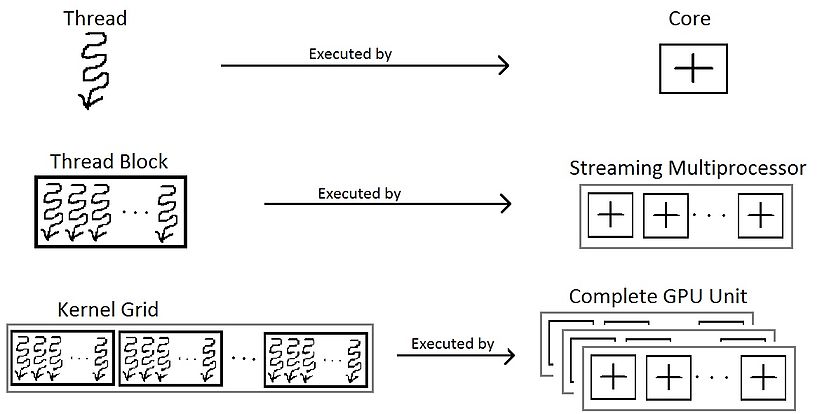
CUDA program execution:
"launching"
the kernel on a grid
|