The NVidoa GPU architecture
This set of slides go into more details on the GPU architecture made by NVidia:
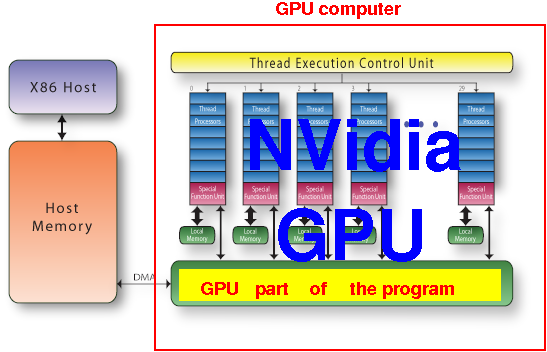
The NVidoa GPU architecture
The NVidia GPU consists of N "stream" multiprocessors that can access a shared device memory:
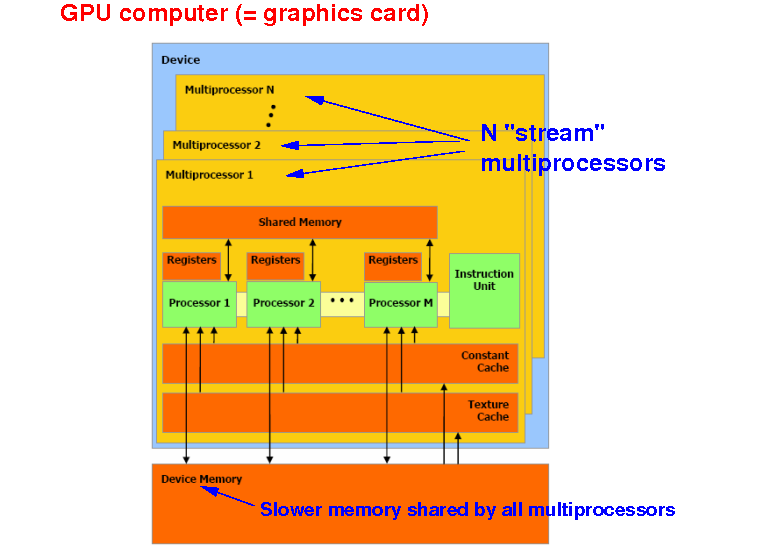
The device memory can be accessed by all multiprocessors (i.e.: a shared memory)
The NVidoa GPU architecture
Each multiprocessor has M processors (a.k.a. CUDA cores ~= ALUs):
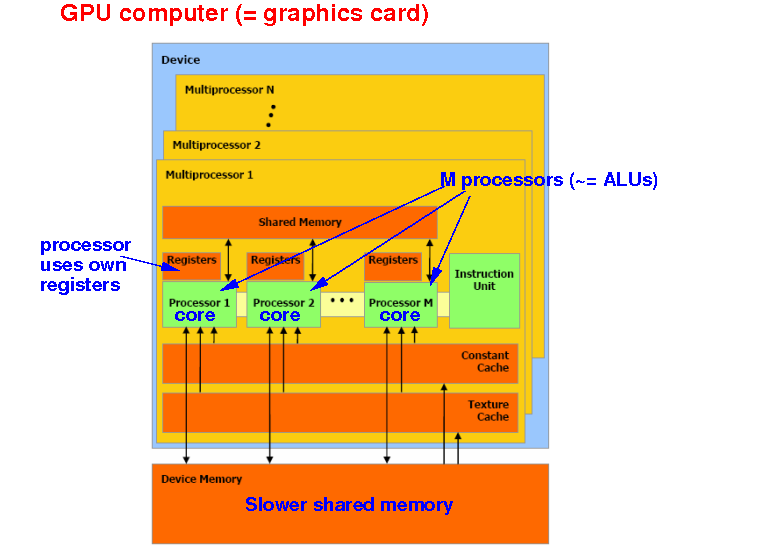
Note:
a processor or
"CUDA core" =
floating point unit
(comparable to an ALU)
( click here
and
click here)
Each processor
or CUDA core (= ALU) uses
its own
registers
Inside the nVidia "Ampere" Multiprocessor
|
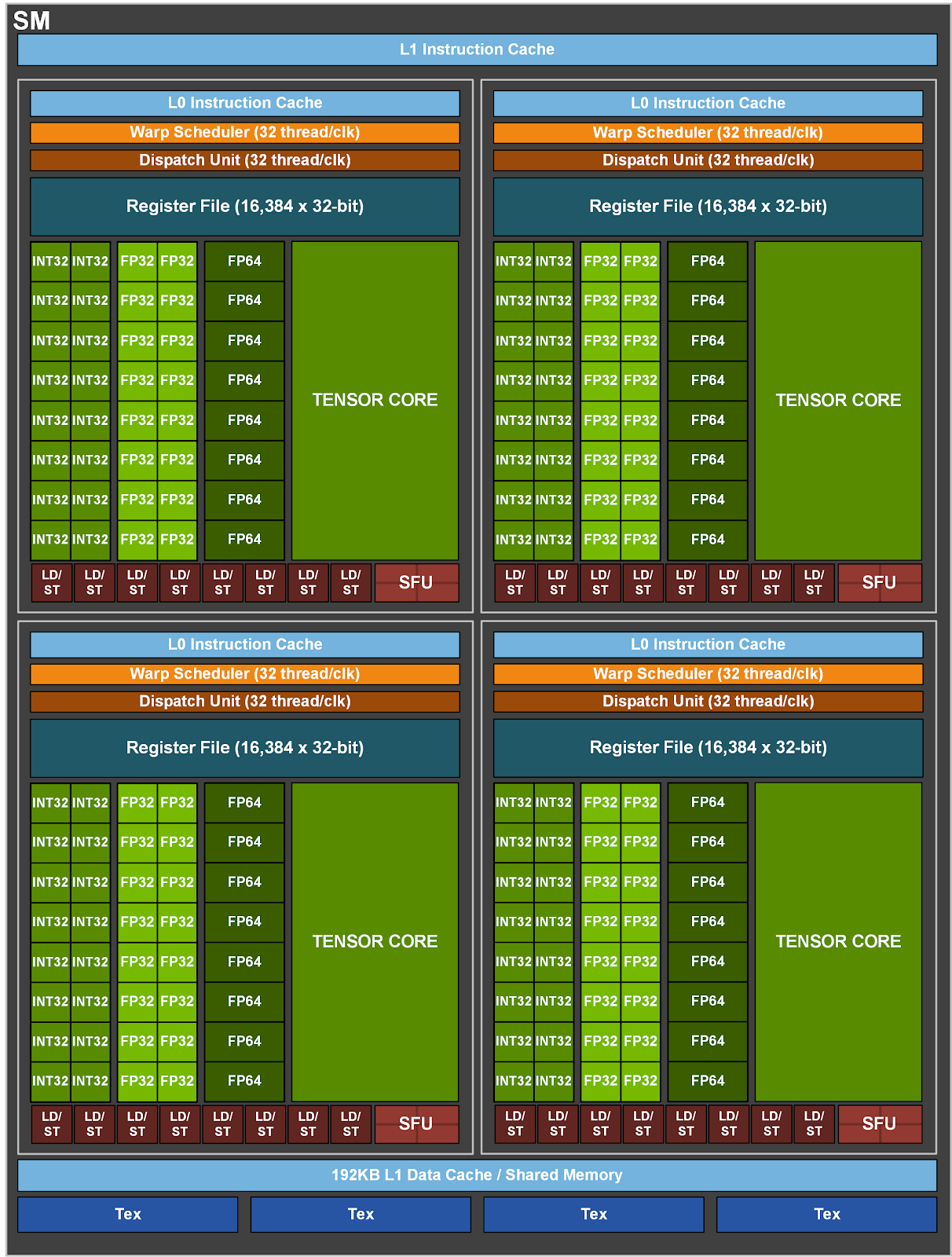
Specification of the
Ampere multiprocessor
|

Execution of threads on a Multi-processor
|
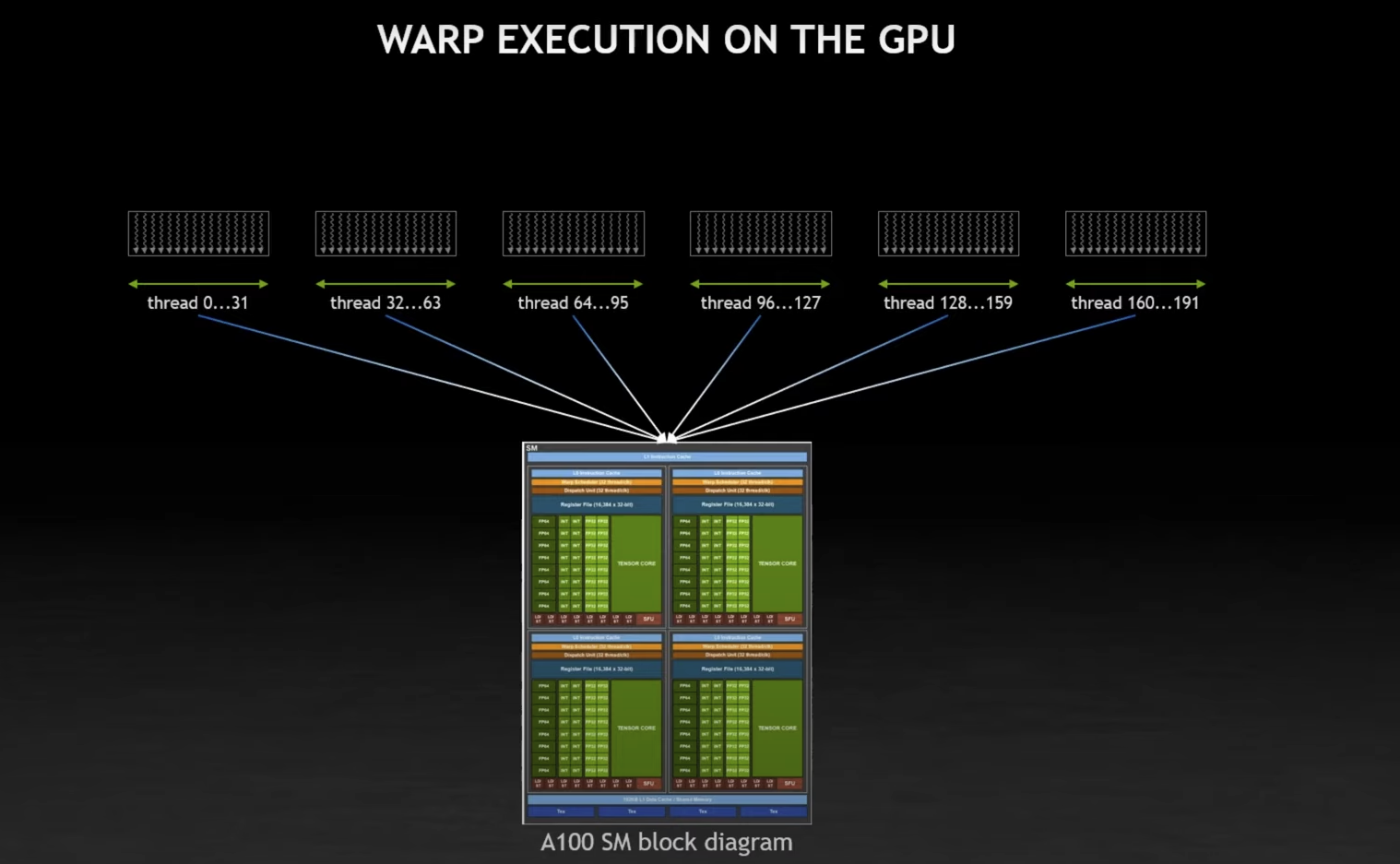
The NVidoa GPU architecture
All cores in the same multiprocessor can also access a (faster) shared memory:
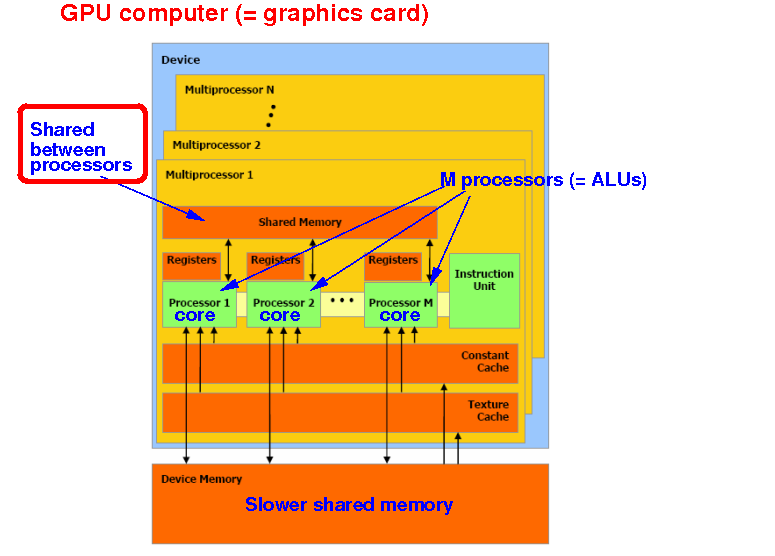
This shared memory enables threads (= programs) running on CUDA cores to communicate with one another
Postscript: CPU cores vs
GPU cores
|