- The most important aspect of parallel programming
that is different from sequential
(i.e., using 1 thread) programming is
synchronization among the various parallel executing
threads that access a common resource
(in our case: shared variables) concurrently.
- Some access operations are
conflicting and
these access operations
cannot be executed simulateneously
Not all access operations are conflicting, however.
- Knowing which accesses are conflicting and
when to protect shared variables from concurrent access
is the key in
writing fast and correct
parallel programs.
- There are 2 access operations:
read and
write
- One common conflicting operations are:
- Reading by one thread and writing by another thread
- Writing by one thread and writing by another thread
- Recall that the global variables can be accessed by all threads
- Recall that threads executes simultaneously, meaning
the (assembler) instructions at multiple places in the program
are executed (by multiple CPUs)
- Recall that when 2 parallel threads try to
update a
shared (global) variable,
some updates can be lost:
Thread 1 on Thread 2 on Memory CPU 1 CPU 2 ============== =================== ================= N = 1234 Read N --> 1234 Add 1 --> 1235 Read N --> 1234 N = 1235 Write N Add 1 --> 1235 N = 1235 Write N
- This phenomenon can be
observed in the following
program:
#include <pthread.h> int N; <========= Shard variable N pthread_t tid[100]; // Each thread executes the following function: void *worker(void *arg) { int i, k, s; for (i = 0; i < 10000; i = i + 1) { N = N + 1; <======= Multiple threads access shared variable N } cout << "Added 10000 to N" << endl; return(NULL); /* Thread exits (dies) */ } /* ======================= MAIN ======================= */ int main(int argc, char *argv[]) { int i, num_threads; num_threads = atoi(argv[1]); /* ------ Create threads ------ */ for (i = 0; i < num_threads; i = i + 1) { if ( pthread_create(&tid[i], NULL, worker, NULL) ) { cout << "Cannot create thread" << endl; exit(1); } } N = 0; // Wait for all threads to terminate for (i = 0; i < num_threads; i = i + 1) pthread_join(tid[i], NULL); cout << "N = " << N << endl << endl; exit(0); }
- Example Program:
(Demo above code)

- Prog file: click here
How to run the program:
- Right click on link and
save in a scratch directory
- To compile: g++ -pthread thread02.C
- To run: ./a.out
-
Obviously, there is a
need to ensure that the parallel thread
execution will
not produce results that is different
from the "normal" result.
- This problem when parallel thread execution can produce abnormal results is called (thread) synchronization problem
- Fact:
- There are many different kinds
of synchronization problems
- Each kind of problem may need to be solved with a special synchronization mechanism (that has certain properties)
- There are many different kinds
of synchronization problems
- Commonly used
synchronization methods (for commonly solved synchronization
problems):
- Mutex (or Mutually exclusive locks):
-
Used to control updates to shared variables
- Read/Write Locks
-
Also used to control access to shared variables, but they are
more "distinguishing" than mutex locks
- Binary and counting semaphores
-
Can be used to synchronize sharing in a more general manner
(not only updating shared variables)
Example: reader/writer problem
- Barriers
-
Can be used to synchronize event horizons
- make sure all involved threads reach a certain point
before proceeding
- Conditional variables (test-and-set operation)
-
Very low-level (hard to use), but very powerful ---
is the basis to implement all the above synchronization methods
in a shared memory programming
model.
- Mutex (or Mutually exclusive locks):
- Not every synchronization methods in CS theory are
implemented in PThreads
- Available synchronization methods in POSIX Threads:
- Mutex lock
- Read-write lock
- Semaphores
- Conditional variable --- too low level for CS355... skipped
- Mutex lock
MUTEX LOCKS
- A mutex lock variable
has 2 values (states)
- Unlocked
- Locked
- A mutex lock
is a synchronization object
with 2 operations:
- Lock
- If the mutex lock is in the
unlocked state,
the lock will
complete (and the thread continues with the next instruction
following the lock
command).
The value (state) of the mutex lock is changed
to locked
- If the mutex lock is in the locked state, the thread that executes the lock command will block (it stops execution) until the value (state) of the mutex lock becomes unlocked (When the state of the mutex lock does become unlocked, the lock command will complete and change the state of the mutex lock to locked)
- If the mutex lock is in the
unlocked state,
the lock will
complete (and the thread continues with the next instruction
following the lock
command).
The value (state) of the mutex lock is changed
to locked
- Unlock
- If the mutex lock is in the
locked state,
the state is changed to
unlocked
- If the mutex lock is in the unlocked state, this operation has no effect.
- The mutex lock can ONLY be unlocked by the thread had previously locked the mutex !!!
- If the mutex lock is in the
locked state,
the state is changed to
unlocked
- Lock
- Defining a mutex lock variable in Pthreads:
pthread_mutex_t x;
- Initializing a mutex variable:
After defining the mutex lock variable, you must initialized it using the following function:
- mutex: is the mutex lock that you want to
initialize (pass the address !)
- attr: is the set of initial property of the mutex lock.
int pthread_mutex_init(pthread_mutex_t *mutex, pthread_mutexattr_t *attr );
The most common mutex lock is one where the lock is initially in the unlock.
This kind of mutex lock is created using the (default) attribute null:
Example: initialize a mutex variable pthread_mutex_t x; /* Define a mutex lock "x" */ pthread_mutex_init(&x, NULL); /* Initialize "x" */
- mutex: is the mutex lock that you want to
initialize (pass the address !)
- Locking a mutex:
- NOTE: although it is possible for pthread_mutex_lock() (and other thread locking functions) to return an error code (see "man pthread_mutex_lock"), it is so rare that we rarely check the return code...
int pthread_mutex_lock(pthread_mutex_t *mutex);
Example: pthread_mutex_t x; pthread_mutex_init(&x, NULL); ... pthread_mutex_lock(&x);
- Unlocking a mutex:
(remember: only the thread that has locked the mutex can
unlock it !)
int pthread_mutex_unlock(pthread_mutex_t *mutex);
Example: pthread_mutex_unlock(&x);
- The jargon "synchronize something"
(like synchronize access) means to organize (through timing)
the different
things (access operations) in such a way that there is
no conflict.
- A common usage of mutex is to synchronize updates
of shared (global) variables
Whenever a thread want to update a shared variable, it must enclose the operation between a "lock - unlock" pair.
Example:
- Although many thread are executing simultaneously,
the statement pthread_mutex_lock(&N_mutex);
ensures that exactly ONE thread
is sucessful in locking the mutex variable N_mutex.
This particular thread will then be the only thread that will update the variable N, thus ensuring that N is updated sequential (one thread after another)
-
Example Program:
(Mutex) ---
click here
Compare the behavior of this program with the one that does not use MUTEX to control access to N: click here
int N; // SHARED variable pthread_mutex_t N_mutex; // Mutex controlling access to N void *worker(void *arg) { int i; for (i = 0; i < 10000; i = i + 1) { pthread_mutex_lock(&N_mutex); N = N + 1; pthread_mutex_unlock(&N_mutex); } } - Although many thread are executing simultaneously,
the statement pthread_mutex_lock(&N_mutex);
ensures that exactly ONE thread
is sucessful in locking the mutex variable N_mutex.
- NOTE:
- Make sure you unlock
a mutex after you are done with
accessing the share variable(s).
A common error in parallel programs is to forget the unlock call (especially if the call is made after many statments)... the result is deadlock - you program hangs (no progress)
-
Example Program:
(Not unlocking a mutex) ---
click here
- Make sure you unlock
a mutex after you are done with
accessing the share variable(s).
- One of the ways that we can estimate the value of Pi is to
compute the definite integral:
Integrate( f(x) = 2.0 / sqrt(1 - x*x) , x = 0 to x = 1 )
Maple: > integrate(2.0 / sqrt(1 - x*x), x=0..1); 3.141592654
Mathematica: (math on W301) In[8]:= Integrate[ 2/Sqrt[1-x*x], {x,0,1} ] Out[8]= Pi - We can use the rectangles
to approximate the
integral
(which is the area under the graph:
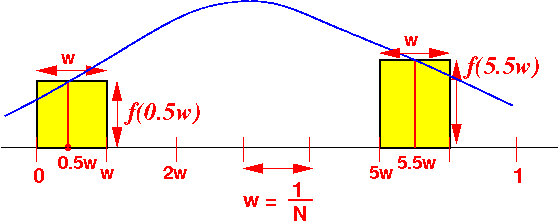
How to approximate:
- Divide the
interval [0..1] into
N sub-intervals
- Each sub-interval has the width of w = 1/N
The sub-interval are:
[0 .. w ] [w .. 2w] [2w .. 3w] ... [.. .. 1]
- The integral over
each sub-interval is
approximate by a
rectangle of:
- Width equal to w
- Height equal to the function value at the middle of the interval
(See the figure above !!!)
- Divide the
interval [0..1] into
N sub-intervals
- From the figure:
We can see that:
Integral ~= w * f(0.5w) + w * f(1.5w) + w + f(2.5w) + ......
In pseudo code:
Integral = 0; for (i = 0; i < N; i++) { x = (i+0.5)*w; Integral = Integral + w * f(x); // w * f(x) is area of rectangle }The entire program in C/C++:
- NOTE: although I am integrating
f(x) = 2.0 / sqrt(1 - x*x) for
x in [0..1],
the program can easily
changed to integrate any function and any interval....
-
Example Program:
(Sequential program for Pi) ---
click here
Compile with:
-
g++ -O compute_pi.C
Run the program with:
-
a.out NumberOfIntervals
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int i; int N; double sum; double x, w; N = ...; // Will determine the accuracy of the approximation w = 1.0/N; sum = 0.0; for (i = 0; i < N; i = i + 1) { x = (i + 0.5) * w; sum = sum + w*f(x); } cout << sum; }
- NOTE: although I am integrating
f(x) = 2.0 / sqrt(1 - x*x) for
x in [0..1],
the program can easily
changed to integrate any function and any interval....
- To obtain a parallel program we must
consider the program were things can be performed
concurrently
-
The best place to look is for loops
Often, a small amount of (shared) information is updated within every execution of the loop.
The program can be speed up when non-conlficting operations are performed concurrently (in parallel), while conlficting operations to the shared information (variable) are performed sequentially
- Example:
- We can perform the
summation mostly in parallel,
BUT: adding
the value to sum - which must be done
serially
(i.e., with synchronization)
- There are different way to divide up the work...
for example,
using 2 threads,
we can divide the summation up as follows:
- Thread 1 compute the "first half" of partial sum
w*(f(0.5w) + f(1.5w) + f(2.5w) + ... + f(0.5-0.5w) )
and thread 2 compute the "second half" of partial sum
w*(f(0.5+0.5w) + f(0.5+1.5w) + f(0.5+2.5w) + ... + f(1-0.5w) )
Pictorially:
values added by values added by thread 1 thread 2 |<--------------------->|<--------------------->| - Thread 1 compute the "even stepped" partial sum
w*(f(0.5w) + f((2 + 0.5)w) + f((4+0.5)w) + ... )
and thread 2 compute the "odd stepped" partial sum
w*(f((1+0.5)w) + f((3+0.5)w) + f((5+0.5)w) + ... ) Pictorially:
values added by thread 1 | | | | | | | | | | | | | | V V V V V V V V V V V V V V |-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-| ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ | | | | | | | | | | | | | | values added by thread 2
It turns out that the "even stepped" and "odd stepped" approach of partition is more easier to program in many instances !!!
NOTE: We don't access any array, so the paging problem is not applicable !!!
The division of labor is as follows for N threads:
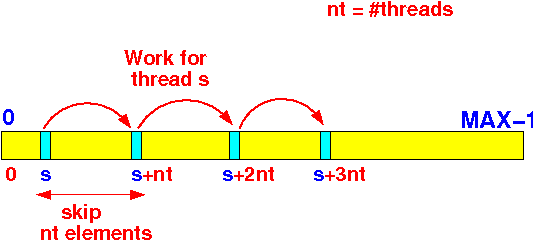
- Thread 1 compute the "first half" of partial sum
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int i; int N; double sum; double x, w; N = ...; // Will determine the accuracy of approximation w = 1.0/N; sum = 0.0; for (i = 0; i < N; i = i + 1) { x = w*(i + 0.5); // We can make x non-shared.. sum = sum + w*f(x); // sum is SHARED !!! } cout << sum; }
- We can perform the
summation mostly in parallel,
BUT: adding
the value to sum - which must be done
serially
(i.e., with synchronization)
- First parallelization attempt:
(with a synchronization bottleneck)
-
Example Program:
(Parallel Pi - version 1) ---
click here
- Compile the program using:
-
g++ -pthread -O -o thread_compute_pi_mt1 thread_compute_pi_mt1.C
- Try run program
on compute.mathcs.emory.edu using:
-
time thread_compute_pi_mt1 1000000 1
time thread_compute_pi_mt1 1000000 4
time thread_compute_pi_mt1 1000000 8 - Then compare the performance numbers with the
non-parallel version:
click here
Are you surprised ???
- Compile the program using:
/*** Shared variables, but not updated.... ***/ int N; // # intervals double w; // width of one interval int num_threads; // # threads /*** Shared variables, updated !!! ***/ double sum; pthread_mutex_t sum_mutex; // Mutex to control access to sum int main(int argc, char *argv[]) { int Start[100]; // Start index values for each thread pthread_t tid[100]; // Used for pthread_join() int i; N = ...; // Read N in from keyboard... w = 1.0/N; // "Broadcast" w num_threads = ... // Skip distance for each thread sum = 0.0; // Initialized shared variable /**** Make worker threads... ****/ for (i = 1; i <= N; i = i + 1) { Start[i] = i; // Start index for thread i if ( pthread_create(&tid[i], NULL, PIworker, &Start[i]) ) { cout << "Cannot create thread" << endl; exit(1); } } /**** Wait for worker threads to finish... ****/ for (i = 0; i < num_threads; i = i + 1) pthread_join(tid[i], NULL); cout << sum; }Worker thread: void *PIworker(void *arg) { int i, myStart; double x; /*** Get the parameter (which is my starting index) ***/ myStart = * (int *) arg; /*** Compute sum, skipping every "num_threads" items ***/ for (i = myStart; i < N; i = i + num_threads) { x = w * ((double) i + 0.5); // next x pthread_mutex_lock(&sum_mutex); sum = sum + w*f(x); // Add to sum pthread_mutex_unlock(&sum_mutex); } return(NULL); /* Thread exits (dies) */ }
-
Example Program:
(Parallel Pi - version 1) ---
click here
- Synchronization bottleneck
- Shared variables are notorous bottlenecks in
parallel programs
- Parallel programs are not always faster than sequential programs -
parallel programs can be slower
due to synchronization overhead (which takes time to execute and
also forces threads to stop running)
- Key to writing fast parallel programs is minimize synchronization to the absolute minimum
- Shared variables are notorous bottlenecks in
parallel programs
- Improved parallelization:
-
Example Program:
(Parallel Pi - version 2) ---
click here
- Compile the program using:
-
g++ -pthread -O -o thread_compute_pi_mt2 thread_compute_pi_mt2.C
- Try run program
on compute.mathcs.emory.edu using:
-
time thread_compute_pi_mt2 1000000 1
time thread_compute_pi_mt2 1000000 4
time thread_compute_pi_mt2 1000000 8 - NOW compare the performance numbers with the
non-parallel version:
click here
- Try: time compute_pi 50000000
- And: time thread_compute_pi_mt2 50000000 8
What a difference it can make where you put the synchronization points in a parallel program....
- Compile the program using:
Worker thread: void *PIworker(void *arg) { int i, myStart; double x; double tmp; // local non-shared variable /*** Get the parameter (which is my starting index) ***/ myStart = * (int *) arg; /*** Compute sum, skipping every "num_threads" items ***/ for (i = myStart; i < N; i = i + num_threads) { x = w * ((double) i + 0.5); // next x tmp = tmp + w*f(x); // No synchr. needed } pthread_mutex_lock(&sum_mutex); sum = sum + tmp; // Synch only ONCE !!! pthread_mutex_unlock(&sum_mutex); return(NULL); /* Thread exits (dies) */ } -
Example Program:
(Parallel Pi - version 2) ---
click here
READ/WRITE LOCKS
- A read/write lock variable
has 3 values (states)
- Unlocked
- Read Locked
- Write Locked
- A read/write lock
is a synchronization object
with 3 operations:
- Read Lock
- If the read/write lock is in the
unlocked state,
the read lock will
complete (and the thread continues with the next instruction
following the read lock
command).
The value (state) of the read/write lock is changed to read locked
- If the read/write lock is in the
read locked state,
the thread that executes the
read lock command
complete (and the thread continues with the next instruction
following the read lock
command).
The value (state) of the read/write lock remains read locked, but a count is increased (so we know how many times a read lock operation has been performed)
- If the read/write lock is in the
write locked state,
the thread that executes the
read lock command
will block (it stops execution)
until the value (state) of the read/write lock becomes
unlocked
(When the state of the read/write lock does become unlocked, the read lock command will complete and change the state of the read/write lock to read locked)
- If the read/write lock is in the
unlocked state,
the read lock will
complete (and the thread continues with the next instruction
following the read lock
command).
- Write Lock
- If the read/write lock is in the
unlocked state,
the write lock will
complete (and the thread continues with the next instruction
following the write lock
command).
The value (state) of the read/write lock is changed to write locked
- If the read/write lock is in the
read locked state,
the thread that executes the
write lock command
will block (it stops execution)
until the value (state) of the read/write lock becomes
unlocked
(When the state of the read/write lock does become unlocked, the write lock command will complete and change the state of the read/write lock to write locked)
- If the read/write lock is in the
write locked state,
the thread that executes the
write lock command
will block (it stops execution)
until the value (state) of the read/write lock becomes
unlocked
(When the state of the read/write lock does become unlocked, the write lock command will complete and change the state of the read/write lock to write locked)
- If the read/write lock is in the
unlocked state,
the write lock will
complete (and the thread continues with the next instruction
following the write lock
command).
- Read Lock
- Difference between mutex and read/write locks:
- Read/write locks is more distinguishing than mutex locks, read/write locks can allow 2 read operations to a shared variable to proceed concurrently
- Defining a read/write lock variable in Pthreads:
pthread_rwlock_t x;
- Initializing a read/write lock variable:
After defining the read/write lock variable, you must initialized it using the following function:
- rwlock: is the read/write lock that you want to
initialize (pass the address !)
- attr: is the set of initial property of the read/write lock.
int pthread_rwlock_init(pthread_rwlock_t *rwlock, pthread_rwlockattr_t *attr );
The most common read/write lock is one where the lock is initially in the unlock.
This kind of mutex lock is created using the (default) attribute null:
Example: a read/write lock with an initial unlock state pthread_rwlock_init(&x, NULL); /* Default initialization */
- rwlock: is the read/write lock that you want to
initialize (pass the address !)
- Read lock a read/write lock:
- NOTE: if a thread already hold a write lock
on a read/write lock, and performs a
pthread_rwlock_rdlock() on that lock, then
the outcome if undefined
(in order words: do NOT try !)
- NOTE: A thread may hold multiple concurrent read locks on a read/write lock (that is, successfully call the pthread_rwlock_rdlock() function n times). If so, the thread must perform matching unlocks (that is, it must call the pthread_rwlock_unlock() function n times).
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
Example: pthread_rwlock_t x; pthread_rwlock_init(&x, NULL); ... pthread_rwlock_rdlock(&x);
- NOTE: if a thread already hold a write lock
on a read/write lock, and performs a
pthread_rwlock_rdlock() on that lock, then
the outcome if undefined
(in order words: do NOT try !)
- Write lock a read/write lock:
- NOTE: if a thread already hold a read lock or write lock on a read/write lock, and performs a pthread_rwlock_wrlock() on that lock, then the outcome if undefined (in order words: do NOT try !)
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
Example: pthread_rwlock_t x; pthread_rwlock_init(&x, NULL); ... pthread_rwlock_wrlock(&x);