Recall that each variable in modern programming languages has:
- a name:
symbolic name used to identify the variable
- an address:
the location in memory where variable is stored
- a type:
see discussion about data type
( click here )
- a scope:
the locations/places/range
where the variable is accessible/visible
- a lifetime: the time (and place) when the variable exists (variables are created and destroyed while the program is running)
- A large program is very complex and difficult to make it
error-free
- The best tool to keep programming simple is
keep information local:
-
Information (variables) that are used and updated by
many different parts of the program will be difficult
to track.
If information (variables) are used or maintained in a some part/section of the program, it is generally easier to make sure that the program is correct.
- Thus, programming languages will allow the program to
create new variables when they are needed; and also
dispose them when they are no longer necessary
- Also, some programming languages have mechanisms to
hide or forbid the use of some variables.
When the program cannot access (is not allowed to use) some variables, the correctness of the program can be maintained with more ease (because the programmer can work more focused).
- We will next discuss the "lifetime" and "scoping" rules for
variables.
Lifetime has to do with when a variable is created and destroyed
Scoping has to do with when a variable is accessible and used.
- When a program is running,
it will - from time to time -
"create some variables"
and
"destroy some variables"
- The jargon "creating a variable" means:
- Reserve space in computer memory to store the value of the variable.
- The jargon "destroying a variable" means:
- Return the space that was reserved for the variable
- NOTE: the space returned can now be used for other variables.
- Clearly, if a variable does NOT exist,
the variable cannot be accessed
Therefore, the scope of every variable is a sub-range of its lifetime
- Some variables can exist
and can be NOT accessible
(Not every veriable that exists is also accessible).

- Scope of a variable
refers to the visibility of a variable.
In other words, which parts of your program can see or use the variable.
- We can also look at scope from the
program perspective:
-
At every point (statement) in the program, there are certain
variables that are visible or accessible.
The collection of all variables that are visible/accessing at a given point is called the program scope
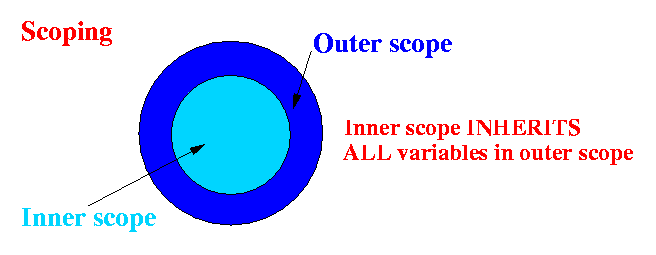
- Modern programming languages
allows the programmer to
define (create) an inner scope
inside an outer scope
And you can define an "inner inner scope" inside the inner scope, and so on (scoping levels can go on indefinitely)
- Scoping Rules in C++:
When you define an inner scope, this inner scope will inherit all variables that are accessible in the outer (enclosing) scope Each time you define an new scope, you can define NEW VARIABLES that will ONLY EXIST in that scope In other words: variables that are defined in a given scope will be destroyed when the scope ends
- Ambigous name resolution:
The two scoping rules creates the following problem:
-
Suppose a variable of name X is defined in the outer scope,
and you define another variable with the same name in the
inner scope.
Which variable does the name X refer to ?
Programming languages use the following name resolution rule:
A name X always refer to an object is defined in the "closest" scope of its occurence. In other words: if the variable X is defined in the current scope, then X will refer to that object.
If X is not defined in the current scope, the program will search outward and locate the first scope in which X is defined. The name X will refer to that object.
- The way to denote the boundary
of a new scope in C/C++
is to use braces:
- { starts a new scope
- } ends the scope
- Example:
..... { (Outer scope) .... .... { (Begin of inner scope) (Inner scope) .... .... } (End of inner scope) .... .... }
- Example: shows inner scope inherits variables from outer scope
int main(int argc, char *argv[]) { int x; x = 1; // int x is accessible after its definition cout << "x = " << x << "\n"; // prints 1 { x = 3.14; // int x is ALSO inside new scope cout << "x = " << x << "\n"; // prints 3 } cout << "x = " << x << "\n"; // prints 3 }- Example Program:
(Demo above code) ---
click here

- Example Program:
(Demo above code) ---
click here
- Example: variable of same name in inner scope
int main(int argc, char *argv[]) { int x; x = 1; // int x is accessible after its definition cout << "x = " << x << "\n"; // prints 1 { float x; <-------------- change x = 3.14; // int x is ALSO inside new scope cout << "x = " << x << "\n"; // prints ??? } cout << "x = " << x << "\n"; // prints ??? }- Example Program:
(Demo above code) ---
click here
- NOTE: Java avoids the problem of having variables
in different scopes that have the same name and makes this
practice illegal as this Java program shows:
click here
- Example Program:
(Demo above code) ---
click here
- Example: accessibility of variable of in inner scope
int main(int argc, char *argv[]) { { float x; <-------------- x = 3.14; // int x is ALSO inside new scope cout << "x = " << x << "\n"; // prints 3.14 } cout << "x = " << x << "\n"; // prints ??? }- Example Program:
(Demo above code) ---
click here
- NOTE: Although Java avoids the problem of having variables
in different scopes that have the same name, it still adopts
the scoping rules in modern programming languages
as this Java program shows:
click here
- Example Program:
(Demo above code) ---
click here
- Global variables in C/C++ are variables
that are NOT defined inside any function
int sum; // Global float f; // variables int main(argc, char *argv[]) { .... } -
Lifetime of global variables
- Global variable begins to exist in the program (space reserved)
when the program begins its execution.
- Global variable ceases to exist in the program (space freed) when the program terminates its execution.
- Global variable begins to exist in the program (space reserved)
when the program begins its execution.
-
C/C++ scoping rule for global variables
- Global variables is visible/accessible in every function except when a local variable of the same name is defined in the given or an outer scope
- Local variables in C/C++ are variables
defined inside a function:
int global1; int main(int argc, char *argv[]) { int local1; .. only local1 accessible (and global1)... { float local2; local1 and local2 (and global1) are accessible } .. only local1 accessible... } float f(float x) { int local3; .. only local3 accessible (and global1)... { float local4; local3 and local4 (and global1) are accessible } .. only local3 accessible... } - Purpose of Local Variables:
- To hold (important) values that is only needed inside the function the where the local variable is defined
- Lifetime of a local variable:
- Begins at the
location where the local variable
is defined
- Ends at the end of the scope in which the local variable is defined
- Begins at the
location where the local variable
is defined
- Scope of a local variable:
- Start at the
location where the local variable is
defined
- Ends at the end of the scope in which the local variable is defined
- Start at the
location where the local variable is
defined
- NOTE: the scoping rules in C/C++ have been illustrated in the above examples....
- Scoping rules may differ in different programming languages
-
In C/C++: a
variable with the same name
in an inner scope
will prevent a variable with that name
in an outer scope to be accessed -
this is called: shadowing
- In Java:
Java does NOT allow shadowing ...
Java will forbid the user to define another variable with the same name in an inner scope
Java adopts a "careful" approach, and tries to prevent the programmer from "confusing oneself"... put it bluntly: Java assumes that you don't know what you're doing...
Java is made for incompetent programmers who do not know what they are doing.... But if you know what you're doing, you will like C++ better.