- The following algorithm can be
very efficient if
an appropriate index is
available:
-
σAttr = constant(R)
--
and there is an index on
the select attribute(s)
-
σAttr ≥ constant(R)
--
and there is an index on
the select attribute(s)
- R ⋈ S -- and there is an index on the join attribute(s)
-
σAttr = constant(R)
--
and there is an index on
the select attribute(s)
- Recall:
clustered and
non-clustered file
(see:
click here
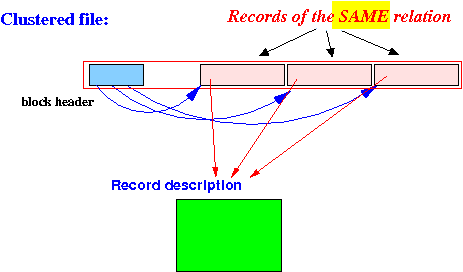
- Clustered file:
- A file that stores
records of
one relation
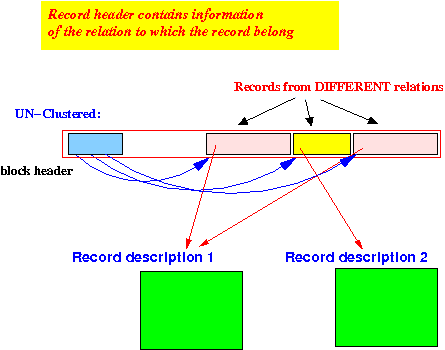
- Unclustered file:
(less common)
- A file that stores
records of
multiple relation
- A file that stores
records of
multiple relation
- A file that stores
records of
one relation
- Clustered file:
- Definition:
clustering index
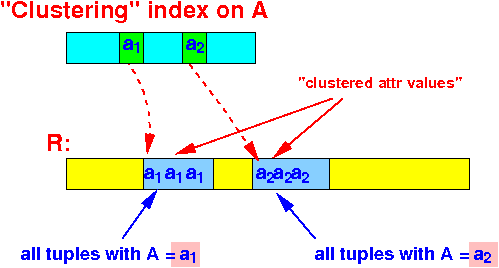
- Clustering index:
- An index on attribute(s) A on
a file is
a clustering index when:
- All tuples with attribute value A = a are stored sequentially (= consecutively) in the data file
Graphically:
- An index on attribute(s) A on
a file is
a clustering index when:
- Clustering index:
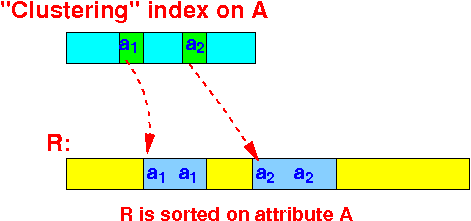
- Common example of a
clustering index:
- When the relation R is
sorted on
the attribute(s) A:
- When the relation R is
sorted on
the attribute(s) A: