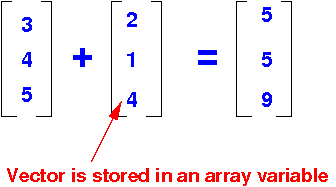
- Vector addition is
adding
corresponding
array elements:
- A CPU version of
the vector addition
algorithm:
float *x, *y; /* ========================================== Allocate arrays to store vector x and y ========================================== */ x = calloc( N, sizeof(float) ); y = calloc( N, sizeof(float) ); /* =============================================== CPU version of the vector addition algorithm =============================================== */ for (i = 0; i < N; i++) // Add N elements... y[i] = x[i] + y[i]; // Add one element at a time...How the program code progresses in time:
- i= 0:

y[0] = x[0] + y[0]:

- i=1:

y[0] = x[0] + y[0]:

And so on....
- i= 0:
- Example Program:
(Demo above code)

cd /home/cs355001/demo/CUDA/3-add-vector/cpu-add-vector.c nvcc -g cpu-add-vector.c -o cpu-add-vector cpu-add-vector 100000 Elasped time = 611 micro secs cpu-add-vector 10000000 Elasped time = 41079 micro secs
- I will now show you a
series of
GPU programs:
- Program 1 is a
GPU program that
identical
to the CPU algorithm
- Program 2 is a
GPU program
that spawn K GPU threads:
- Each GPU thread will compute N/K sums of the total N sums
- Program 3 is a
GPU program
that spawn N GPU threads:
- Each GPU thread will compute exactly 1 sum of the total N sums
(This version is completely data parallel)
- Program 1 is a
GPU program that
identical
to the CPU algorithm
- The CPU algorithm is:
/* ================================================== "Serial" version of the vector addition algorithm ================================================== */ for (i = 0; i < N; i++) y[i] = x[i] + y[i]; // Add 1 element at a time
- The CUDA program that
runs the
CPU algorithm with
the GPU processor:
__global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) // Same code as CPU version y[i] = x[i] + y[i]; } int main(int argc, char *argv[]) { ... initialization code omitted .... // ======================================================================= // Run "add" kernel on on the GPU using 1 block, 1 thread/per block add<<<1, 1>>>(N, x, y); // Call CPU function // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Wait for GPU to finish // ======================================================================= ... print code omitted ... }How the program code progresses in time:
- i= 0:
y[0] = x[0] + y[0]:
- i=1:
y[0] = x[0] + y[0]:
And so on....
- i= 0:
- Example Program:
(Demo above code)
file: /home/cs355001/demo/CUDA/3-add-vector/add-vector1.cu Compile: nvcc -o add-vector1 add-vector1.cu Sample runs: cs355@ghost01 (1457)> add-vector1 100000 Elasped time = 18492 micro secs cs355@ghost01 (1458)> add-vector1 10000000 Elasped time = 1604292 micro secs
Conclusion:
- The GPU is
slower than the
CPU !!!
(But we are not using the GPU the right way --- GPU are parallel processors and we only run 1 thread -- no parallel execution inside the GPU !!!)
- The GPU is
slower than the
CPU !!!
- Execution organization:
- We will launch
a grid of
K threads ("workers")
to be runned on the GPU:
add<<<1, K>>>(N, x, y);
We will distribute the computations among these K threads (workers)...
- How to
divide the
work load between
K "workers" (= GPU threads):
- Thread 0 performs
the following
computations:

- Thread 1 performs
the following
computations:

- And so on !!!
Conclusion:
- Thread i must start at A[i]
- The skip distance (for every thread is # threads
- Thread 0 performs
the following
computations:
- We will launch
a grid of
K threads ("workers")
to be runned on the GPU:
- The CUDA program is
as follows:
int main(int argc, char *argv[]) { ... initialization code omitted ... // ================================================================== // Run kernel on the GPU using 1 block, K thread/per block add<<<1, K>>>(N, x, y); // Spawn K GPU threads // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Wait for GPU to finish // ================================================================== ... print code omitted ... }
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; // Get my ID -> start with this index int stride = blockDim.x; // Get the # threads -> skip distance if ( blockDim.x < 10 ) printf("Running (%d,%d)\n", blockIdx.x, threadIdx.x); for (int i = index; i < n; i = i + stride) { y[i] = x[i] + y[i]; // Worker "index" computes: // index, index+K, index+2K, ... } }
- Example Program:
(Demo above code)
Program file: /home/cs355001/demo/CUDA/3-add-vector/vector-add2.cu Compile: nvcc -o add-vector2 add-vector2.cu Sample runs: cs355@ghost01 (1475)> add-vector2 10000000 1 (1 thread) Elasped time = 2106604 micro secs cs355@ghost01 (1479)> add-vector2 10000000 10 (10 threads !!) Elasped time = 328381 micro secs cs355@ghost01 (1480)> add-vector2 10000000 100 Elasped time = 56360 micro secs
- Execution organization:
- We will launch
a grid of
N threads ("workers")
to be runned on the GPU !!!
- N = the number of elements in the vector !!!
We can do this, because CUDA can use an insane number of threads:
- A grid can have 2147483647 blocks and
- each block can have 1024 threads
- Divide the
work load between
N "workers" (= GPU threads):
- Thread 0 performs
the following
computations:

- Thread 1 performs
the following
computations:

- And so on !!!
- Thread 0 performs
the following
computations:
- We will launch
a grid of
N threads ("workers")
to be runned on the GPU !!!
- The CUDA program is
as follows:
__global__ void add(int n, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if ( i < n ) // NO LOOP !!! { y[i] = x[i] + y[i]; // Work load for thread i !!! } }
int main(int argc, char *argv[]) { ... initialization code omitted ... int K = # threads in a block; // ================================================================== int NBlks = ceil( (float) N / K ); // Compute how many blocks we will need to use add<<<NBlks, K>>>(N, x, y); // Spawn NBlks*K GPU threads // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Wait for GPU to finish // ================================================================== ... print code omitted ... }
- Example Program:
(Demo above code)
Program file: /home/cs355001/demo/CUDA/3-add-vector/vector-add3.cu Compile: nvcc -o add-vector3 add-vector3.cu Sample runs: cs355@ghost01 (1475)> add-vector3 10000000 1 (1 thread/blk) User specified to use K=1 threads/block N = 10000000/1 = 10000000.000000 ---> we must use 10000000 blocks Elasped time = 92493 micro secs cs355@ghost01 (1751)> add-vector3 10000000 32 (32 threads/blk) User specified to use K=32 threads/block N = 10000000/32 = 312500.000000 ---> we must use 312500 blocks Elasped time = 21408 micro secs cs355@ghost01 (1752)> add-vector3 10000000 64 User specified to use K=64 threads/block N = 10000000/64 = 156250.000000 ---> we must use 156250 blocks Elasped time = 20970 micro secs