CUDA programming
before the
introduction of
Unified Memory
|
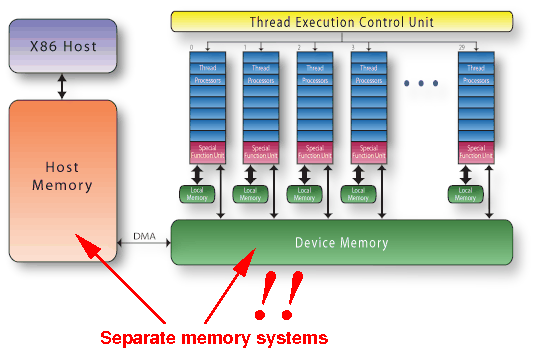
Allocating
host (CPU) memory and
device (GPU) memory
|
Transfer data between
host (CPU) memory and
device (GPU) memory
|
The host program of
Vector Addition
without
using Unified Memory
|
The host program of
Vector Addition
without
using Unified Memory
|
The host program of
Vector Addition
without
using Unified Memory
|
The host program of
Vector Addition
without
using Unified Memory
|
The host program of
Vector Addition
without
using Unified Memory
|
The host program of
Vector Addition
without
using Unified Memory
|
DEMO: demo/CUDA/3-add-vector/gpu-add-vector2.cu