Review:
the memories in a
CPU/GPU computer system
Recall: the host memory and device memory are separate memory systems
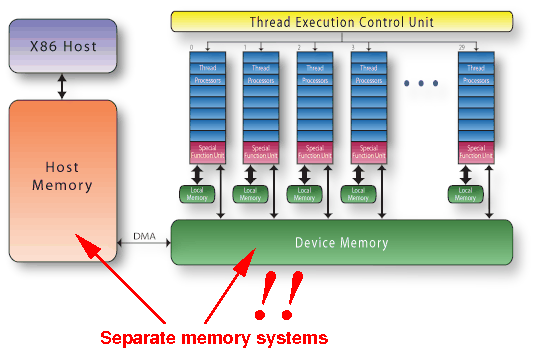
Review:
the memories in a
CPU/GPU computer system
Data used by CPU and GPU must be transfered between host memory and device memory:
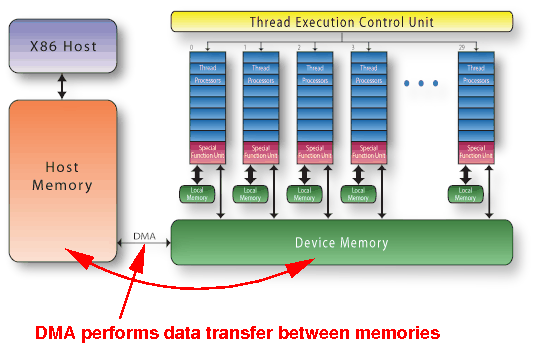
How data transfer operations between
RAM and device memory are
performed in
CUDA
|
CUDA's Unified memory
Unified memory = a memory model (implemented with system software by NVidia) presented to the CUDA programmer where the CPU and the GPU "sees" the same computer memory:

Recall: the CPU and GPU have separate memories !!!
Using hardware support, NVidia wrote software that performs a data transfer operation between the CPU/GPU memories when needed !!
How does the
unified memory work ?
The CUDA "C part" program defines a variable and specifies it as __managed__:

__managed__ variables are stored in both RAM and dev memory !
How does the
unified memory work ?
Initially, the copy of a __managed__ variable in the host memory (RAM) is "active":

.... and the copy of a __managed__ variable in the device memory is "inactive"
How does the
unified memory work ?
CPU code can update a (active) __manage__ variable:

The copy in the device memory is not updated by a CPU operation on the RAM copy !!
How does the
unified memory work ?
When some GPU code wants to use (= read/write) an inactive __manage__ variable:

The access operation will trigger the Unified memory subsystem to perform an automated transfer operation first !
How does the
unified memory work ?
The Unified memory software will transfer the active copy to the inactive:

... and swap the active/inactive states !!
How does the
unified memory work ?
After the transfer, the GPU access operation is executed:

So the GPU will always use the latest updated value in a __managed__ variable !!
How does the
unified memory work ?
If later, the CPU code accesses the __managed__ variable:

Accessing the inactive copy of a __managed__ variable will trigger a transfer operation again first...
How does the
unified memory work ?
The Unified memory subsystem first transfer the data:

... and swap the active/inactive states
How does the
unified memory work ?
Then proceed with the access (= read or write) operation:

There is one caveat in using
Unified memory !!
Caveat:: the on-demand transfer operation happens at the moment the CPU/GPU access the __managed__ variable

Therefore:: You must make sure that the CPU/GPU program(s) (that run concurrently) have completed the computation when a managed variable is used/accessed !!!
Example of using unified memory
We like to write a CUDA program with the following program flow:
CPU CUDA program GPU CUDA program
---------------- ----------------
__managed__ int x (shared variable)
x = 1234; // (1) Init x
Launch a GPU kernel
that increments x; -------> Kernel:
print(x); // (2) Prints int value
x++; // (3) Incr x
|
+------------------------- +
|
V
print(x); // (4) Prints incr value
|
I will first show you a wrong program; then a corrected one...
Example of a case where the GPU
did not finish
update in time
Consider the following CUDA program: (CPU fails to see the update !)
#include <stdio.h>
#include <unistd.h>
__managed__ int x; // Defines shared variable !!!
__global__ void GPU_func( )
{
printf("GPU sees x = %d\n", x);
x++;
}
int main()
{
x = 1234;
GPU_func<<< 1, 1 >>>( ); // Run 1 thread
printf("CPU sees x = %d\n", x); // Transfer x happens HERE
cudaDeviceSynchronize( ); // Wait for GPU to finish
}
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of a case where the GPU
did not finish
update in time
Why did the CPU fail to see the update: initial state
time CPU GPU
------------------ ------------------
| x (active) = ? x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) print(x)
|
| print(x) x++;
|
| Synchronize( );
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of a case where the GPU
did not finish
update in time
The CPU executes x=1234:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) print(x)
|
| print(x) x++;
|
| Synchronize( );
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of a case where the GPU
did not finish
update in time
The CPU launches one CUDA thread:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| print(x) x++;
|
| Synchronize( );
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of a case where the GPU
did not finish
update in time
A kernel launch is asynchronous and the CPU will continue with its execution:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| print(x) x++;
|
| Synchronize( );
V
Output:
CPU sees x = 1234 // That's why we see this first !
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of a case where the GPU
did not finish
update in time
Synchronize( ) makes the CPU program wait for the GPU kernel to finish:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| print(x) x++;
|
| Synchronize( );
V
Output:
CPU sees x = 1234 // That's why we see this first !
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of a case where the GPU
did not finish
update in time
Now, the GPU executes print(x):
time CPU GPU
------------------ ------------------
| x (inactive) = 1234 x (active) = 1234
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| print(x) x++;
|
| Synchronize( );
V
Output:
CPU sees x = 1234 // That's why we see this first !
GPU sees x = 1234 // That's why we see this next !
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global-fail.cu
Example of correct use of
Unified Memory
The following CUDA program implements the behavior correctly:
#include <stdio.h> #include <unistd.h> __managed__ int x; // Defines shared variable !!! __global__ void GPU_func( ) { printf("GPU sees x = %d\n", x); x++; } int main() { x = 1234; GPU_func<<< 1, 1 >>>( ); // Run 1 thread cudaDeviceSynchronize( ); // Wait for GPU to finish printf("CPU sees x = %d\n", x); // Transfer x happens HERE } |
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
Why did the CPU succeed to see the update: initial state
time CPU GPU
------------------ ------------------
| x (active) = ? x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) print(x)
|
| Synchronize( ); x++;
|
| print(x);
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
The CPU executes x=1234:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) print(x)
|
| Synchronize( ); x++;
|
| print(x);
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
The CPU launches one CUDA thread:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| Synchronize( ); x++;
|
| print(x);
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
A kernel launch is asynchronous and the CPU will continue with its execution:
time CPU GPU
------------------ ------------------
| x (active) = 1234 x (inactive) = ?
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| Synchronize( ); *wait* x++;
|
| print(x);
V
Output:
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
Later, the GPU executes print(x):
time CPU GPU
------------------ ------------------
| x (inactive) = 1234 x (active) = 1234
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| Synchronize( ); *wait* x++;
|
| print(x);
V
Output:
GPU sees x = 1234 // That's why we see this first !
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
Then the GPU executes x++:
time CPU GPU
------------------ ------------------
| x (inactive) = 1234 x (active) = 1235
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| Synchronize( ); *wait* x++;
|
| print(x);
V
Output:
GPU sees x = 1234 // That's why we see this first !
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
The GPU finishes execution and the CPU will synchronize successfully:
time CPU GPU
------------------ ------------------
| x (inactive) = 1234 x (active) = 1235
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| Synchronize( ); *DONE* x++;
|
| print(x);
V
Output:
GPU sees x = 1234 // That's why we see this first !
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu
Example of correct use of
Unified Memory
The CPU executes print(x) and causes a transfer:
time CPU GPU
------------------ ------------------
| x (active) = 1235 x (inactive) = 1235
|
| x = 1234
|
| GPU_func( ) launch--> print(x)
|
| Synchronize( ); *DONE* x++;
|
| print(x);
V
Output:
GPU sees x = 1234 // That's why we see this first !
CPU sees x = 1235
|
DEMO: /home/cs355001/demo/CUDA/2-unified-mem/shared-global.cu