Brief history of
GPU computing
|
For more info: click here
The CUDA Architecture
|
The CUDA architecture
The CUDA architecture makes the GPU computer as a subsystem of a CPU (host) computer:

The CUDA architecture
The CPU system and the GPU (sub)system have their own (independent) memories:
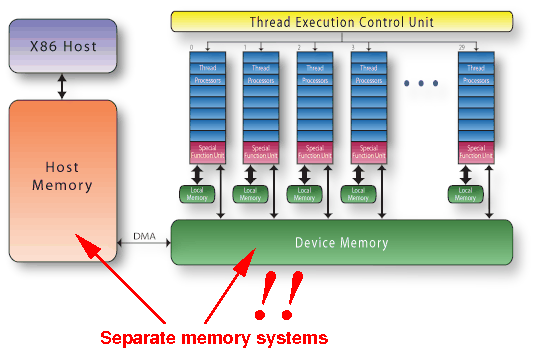
The CUDA architecture
Consequently: data must be transfered between RAM and device memory (using DMA):
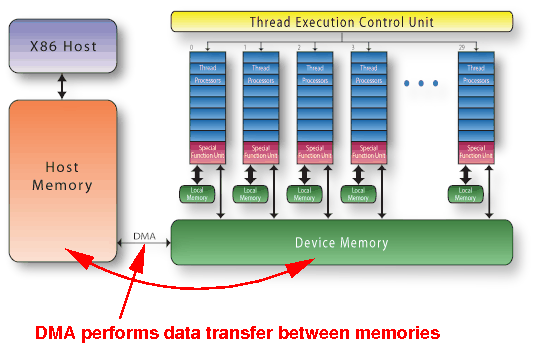
CUDA programming
A CUDA (computer) program consists of 2 parts:

(1) a CPU part of the CUDA program stored in RAM (and executed by the CPU)
CUDA programming
A CUDA (computer) program consists of 2 parts:

(2) a GPU part of the CUDA program stored in the device memory (and executed by the GPU)
How to write the CPU program part of a
CUDA program
|
How to write the GPU program part of a
CUDA program
|
Note: CUDA C is designed to be similar to the C language to make it easy to learn !!!
How does the
GPU execute a
CUDA function
|

Threads
|