- One of the ways that we can estimate the value of Pi is to
compute the definite integral:
Integrate( f(x) = 2.0 / sqrt(1 - x*x) , x = 0 to x = 1 )
Maple: > integrate(2.0 / sqrt(1 - x*x), x=0..1); 3.141592654
Mathematica: (math on W301) In[8]:= Integrate[ 2/Sqrt[1-x*x], {x,0,1} ] Out[8]= Pi
Matlab: (matlab -nodesktop) >> syms x; >> ans = int( 2/sqrt(1-x*x),0,1 ); >> disp(ans) piReason:
integral of 2 / sqrt( 1 - x^2 ) = 2 × arcsin( x ) arcsin(1) = 1/2 Pi arcsin(0) = 0
- We can use the rectangles
to approximate the
integral
(which is the area under the graph:
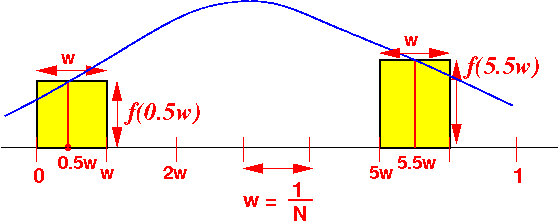
How to approximate:
- Divide the
interval [0..1] into
N sub-intervals
- Each sub-interval has the width of w = 1/N
The sub-interval are:
[0 .. w ] [w .. 2w] [2w .. 3w] ... [.. .. 1]
- The integral over
each sub-interval is
approximate by a
rectangle of:
- Width equal to w
- Height equal to the function value at the middle of the interval
(See the figure above !!!)
- Divide the
interval [0..1] into
N sub-intervals
- From the figure:
We can see that:
Integral ~= w * f(0.5w) + w * f(1.5w) + w + f(2.5w) + ......
In pseudo code:
Integral = 0; for (i = 0; i < N; i++) { x = (i+0.5)*w; Integral = Integral + w * f(x); // w * f(x) is area of rectangle }The entire program in C/C++:
- NOTE: although I am integrating
f(x) = 2.0 / sqrt(1 - x*x) for
x in [0..1],
the program can easily
changed to integrate any function and any interval....
-
Example Program:
(Sequential program for Pi) ---
click here

Compile with:
-
g++ -O compute_pi.C
Run the program with:
-
a.out NumberOfIntervals
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int i; int N; double sum; double x, w; N = ...; // Will determine the accuracy of the approximation w = 1.0/N; sum = 0.0; for (i = 0; i < N; i = i + 1) { x = (i + 0.5) * w; sum = sum + w*f(x); } cout << sum; }
- NOTE: although I am integrating
f(x) = 2.0 / sqrt(1 - x*x) for
x in [0..1],
the program can easily
changed to integrate any function and any interval....
- To obtain a parallel program we must
consider the program were things can be performed
concurrently
-
The best place to look is for loops
Often, a small amount of (shared) information is updated within every execution of the loop.
The program can be speed up when non-conlficting operations are performed concurrently (in parallel), while conlficting operations to the shared information (variable) are performed sequentially
- Example:
- We can perform the
summation mostly in parallel,
BUT: adding
the value to sum - which must be done
serially
(i.e., with synchronization)
- There are different way to divide up the work...
for example,
using 2 threads,
we can divide the summation up as follows:
- Thread 1 compute the "first half" of partial sum
w*(f(0.5w) + f(1.5w) + f(2.5w) + ... + f(0.5-0.5w) )
and thread 2 compute the "second half" of partial sum
w*(f(0.5+0.5w) + f(0.5+1.5w) + f(0.5+2.5w) + ... + f(1-0.5w) )
Pictorially:
values added by values added by thread 1 thread 2 |<--------------------->|<--------------------->| - Thread 1 compute the "even stepped" partial sum
w*(f(0.5w) + f((2 + 0.5)w) + f((4+0.5)w) + ... )
and thread 2 compute the "odd stepped" partial sum
w*(f((1+0.5)w) + f((3+0.5)w) + f((5+0.5)w) + ... ) Pictorially:
values added by thread 1 | | | | | | | | | | | | | | V V V V V V V V V V V V V V |-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-| ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ | | | | | | | | | | | | | | values added by thread 2
It turns out that the "even stepped" and "odd stepped" approach of partition is more easier to program in many instances !!!
NOTE: We don't access any array, so the paging problem is not applicable !!!
The division of labor is as follows for N threads:
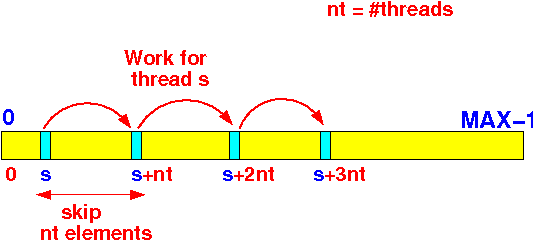
- Thread 1 compute the "first half" of partial sum
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int i; int N; double sum; double x, w; N = ...; // Will determine the accuracy of approximation w = 1.0/N; sum = 0.0; for (i = 0; i < N; i = i + 1) { x = w*(i + 0.5); // We can make x non-shared.. sum = sum + w*f(x); // sum is SHARED !!! } cout << sum; }
- We can perform the
summation mostly in parallel,
BUT: adding
the value to sum - which must be done
serially
(i.e., with synchronization)
- First parallelization attempt:
(with a synchronization bottleneck)
-
Example Program:
(Parallel Pi - version 1) ---
click here
- Compile the program using:
-
g++ -pthread -O -o thread_compute_pi_mt1 thread_compute_pi_mt1.C
- Try run program
on compute.mathcs.emory.edu using:
-
time thread_compute_pi_mt1 1000000 1
time thread_compute_pi_mt1 1000000 4
time thread_compute_pi_mt1 1000000 8 - Then compare the performance numbers with the
non-parallel version:
click here
Are you surprised ???
- Compile the program using:
/*** Shared variables, but not updated.... ***/ int N; // # intervals double w; // width of one interval int num_threads; // # threads /*** Shared variables, updated !!! ***/ double sum; pthread_mutex_t sum_mutex; // Mutex to control access to sum int main(int argc, char *argv[]) { int Start[100]; // Start index values for each thread pthread_t tid[100]; // Used for pthread_join() int i; N = ...; // Read N in from keyboard... w = 1.0/N; // "Broadcast" w num_threads = ... // Skip distance for each thread sum = 0.0; // Initialized shared variable /**** Make worker threads... ****/ for (i = 1; i <= N; i = i + 1) { Start[i] = i; // Start index for thread i if ( pthread_create(&tid[i], NULL, PIworker, &Start[i]) ) { cout << "Cannot create thread" << endl; exit(1); } } /**** Wait for worker threads to finish... ****/ for (i = 0; i < num_threads; i = i + 1) pthread_join(tid[i], NULL); cout << sum; }Worker thread: void *PIworker(void *arg) { int i, myStart; double x; /*** Get the parameter (which is my starting index) ***/ myStart = * (int *) arg; /*** Compute sum, skipping every "num_threads" items ***/ for (i = myStart; i < N; i = i + num_threads) { x = w * ((double) i + 0.5); // next x pthread_mutex_lock(&sum_mutex); sum = sum + w*f(x); // Add to sum pthread_mutex_unlock(&sum_mutex); } return(NULL); /* Thread exits (dies) */ }
-
Example Program:
(Parallel Pi - version 1) ---
click here
- Synchronization bottleneck
- Shared variables are notorous bottlenecks in
parallel programs
- Parallel programs are not always faster than sequential programs -
parallel programs can be slower
due to synchronization overhead (which takes time to execute and
also forces threads to stop running)
- Key to writing fast parallel programs is minimize synchronization to the absolute minimum
- Shared variables are notorous bottlenecks in
parallel programs
- Improved parallelization:
-
Example Program:
(Parallel Pi - version 2) ---
click here
- Compile the program using:
-
g++ -pthread -O -o thread_compute_pi_mt2 thread_compute_pi_mt2.C
- Try run program
on compute.mathcs.emory.edu using:
-
time thread_compute_pi_mt2 1000000 1
time thread_compute_pi_mt2 1000000 4
time thread_compute_pi_mt2 1000000 8 - NOW compare the performance numbers with the
non-parallel version:
click here
- Try: time compute_pi 50000000
- And: time thread_compute_pi_mt2 50000000 8
What a difference it can make where you put the synchronization points in a parallel program....
- Compile the program using:
Worker thread: void *PIworker(void *arg) { int i, myStart; double x; double tmp; // local non-shared variable /*** Get the parameter (which is my starting index) ***/ myStart = * (int *) arg; /*** Compute sum, skipping every "num_threads" items ***/ for (i = myStart; i < N; i = i + num_threads) { x = w * ((double) i + 0.5); // next x tmp = tmp + w*f(x); // No synchr. needed } pthread_mutex_lock(&sum_mutex); sum = sum + tmp; // Synch only ONCE !!! pthread_mutex_unlock(&sum_mutex); return(NULL); /* Thread exits (dies) */ } -
Example Program:
(Parallel Pi - version 2) ---
click here