How the pipeline CPU executes
multiple instructions
Clock cycle 1: The IF stage fetches the 1st instruction into the IR(ID) register
Watch carefully at the operation performed by each individual stage !! (It's exactly like before)
How the pipeline CPU executes
multiple instructions
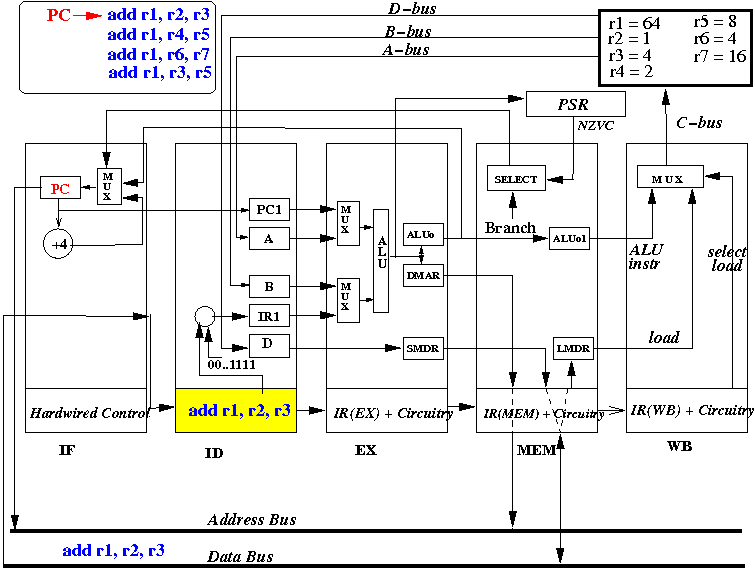
Start 2: ID stage fetches all possible source operands, IF stage fetches the next instruction
How the pipeline CPU executes
multiple instructions
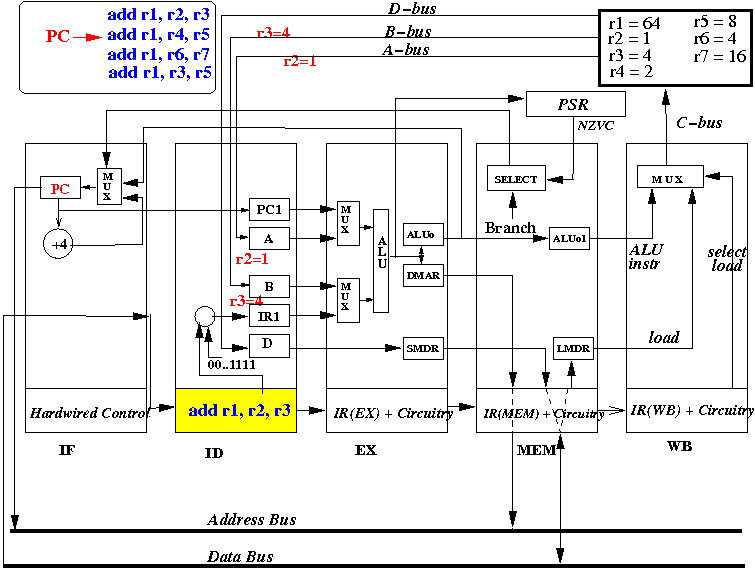
End 2: all source operands for add r1,r2,r3 are fetched and next instruction fetched
Notice: the instruction add r1,r2,r3 is moved into the IR(EX) register
How the pipeline CPU executes
multiple instructions
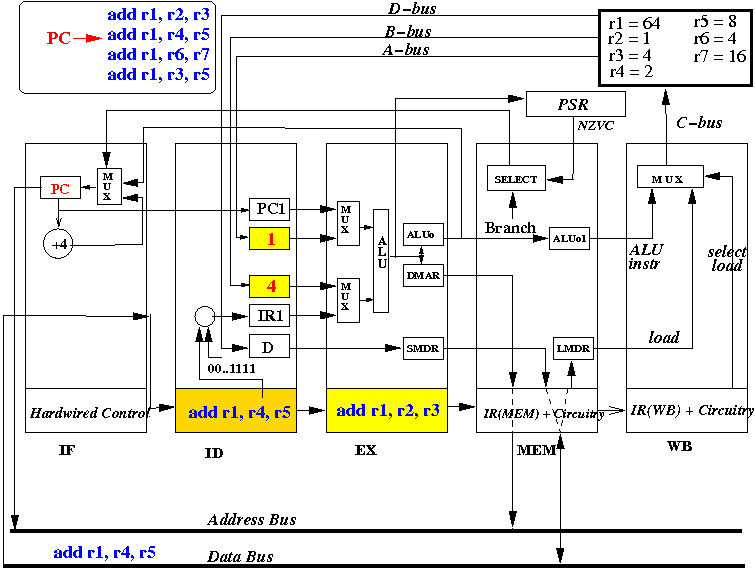
Start 3: EX stage operates, ID stage fetches ops, IF stage fetches instr
How the pipeline CPU executes
multiple instructions
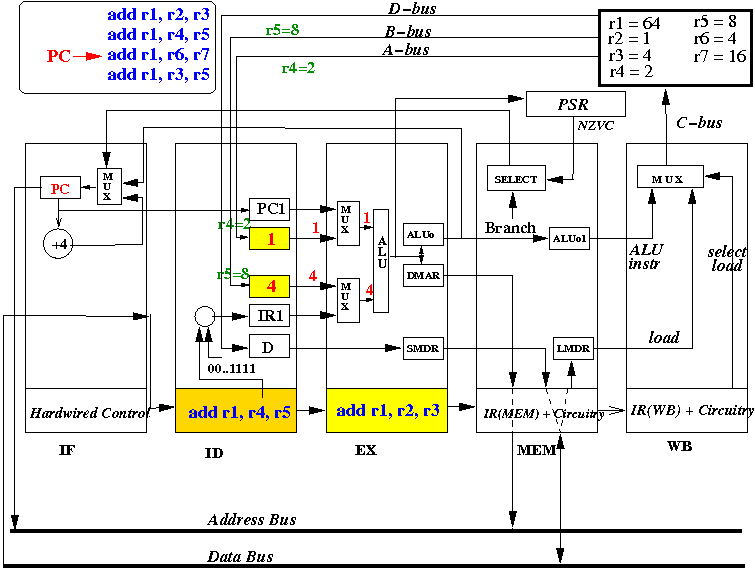
End 3: results in all stages are stored away
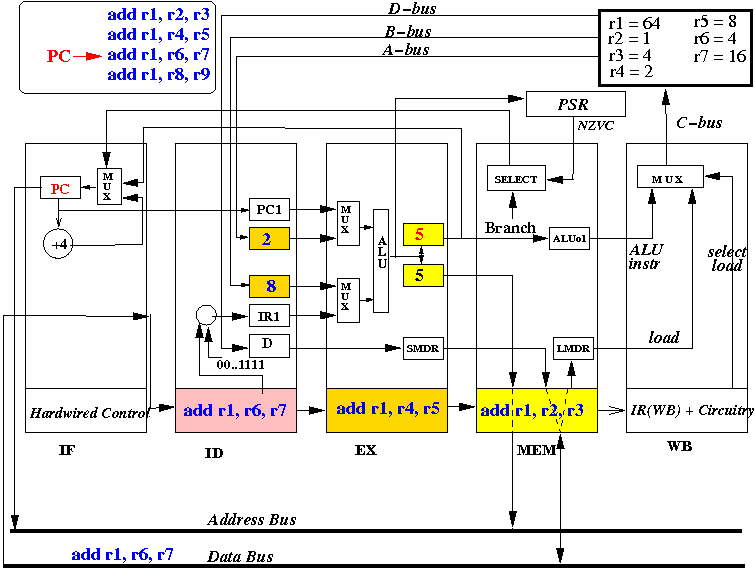
Notice: all instructions are moved forward
How the pipeline CPU executes
multiple instructions
Start 4: MEM: forwards, EX: operates, ID stage fetches ops, IF stage fetches instr

How the pipeline CPU executes
multiple instructions
End 4: results in all stages are stored away
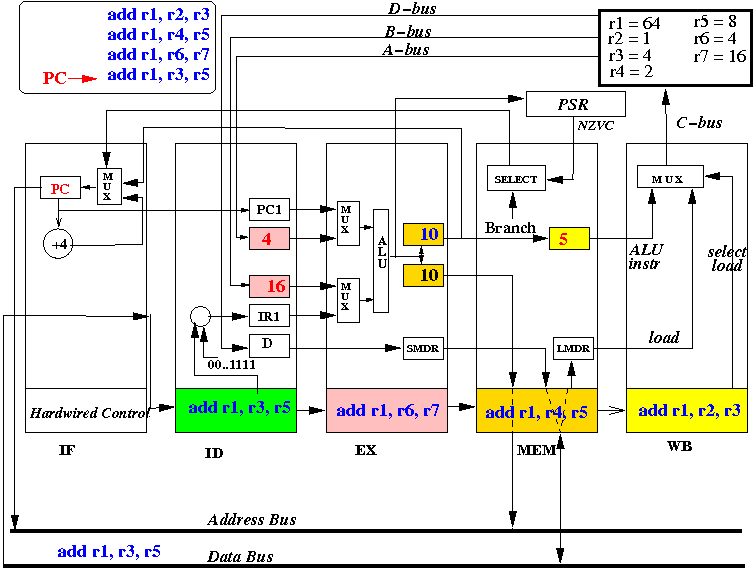
Notice: all instructions are moved forward
How the pipeline CPU executes
multiple instructions
Start 5: WB: update R1, MEM: forwards, EX: operates, ID: fetches ops, IF: fetches instr
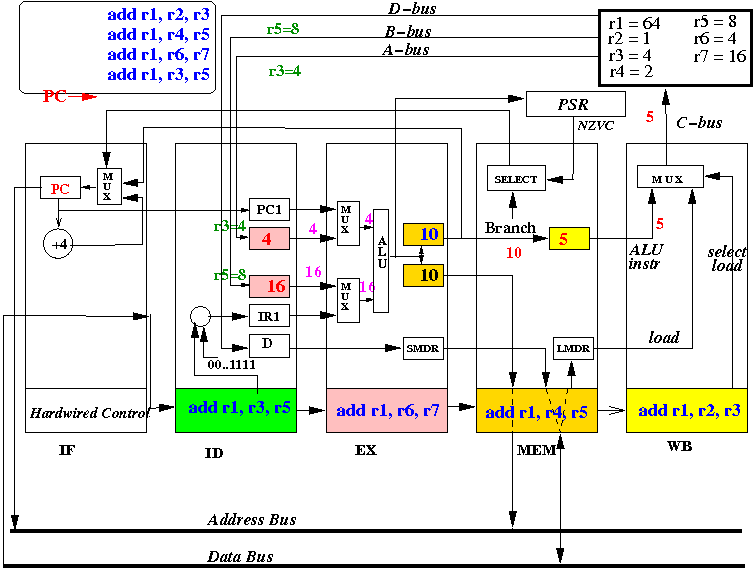
How the pipeline CPU executes
multiple instructions
End 5: results in all stages are stored away
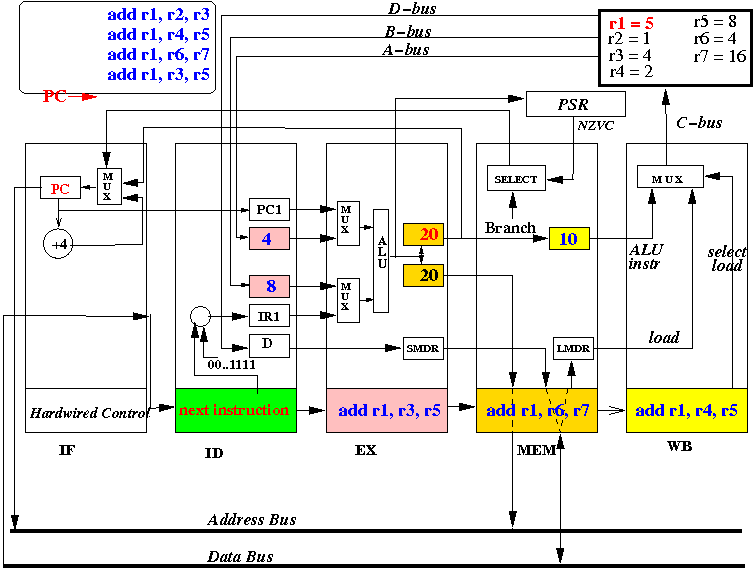
Notice the significant speed up !!!
DEMO (using Aaron's pipelined CPU)
|